韩国公共机构至今仍然大量使用扩展名为 .hwp 的文件。
这种文件是韩文和计算机公司打造的自有规范文档格式。
问题在于,这种格式并不能与其他程序做到完全兼容。
要把文档“打开来看”当然是可以的。
但要能以结构化的方式读取其内容,并像数据一样加以利用,那又是完全不同的问题。
而恰恰在这一点上,它成了在用 AI 处理公共文书时最大的障碍。
1. 公文解析为何困难——hwp
HWP 不是单纯的文档文件。
因为是专为韩文设计的二进制格式,人眼阅读和机器做结构化解析完全是两回事。
仅仅把文件打开本身也许没什么难度。
但要能按段落、表格、条目、格式等语义单位稳定地解析,就要困难得多。
原因很简单。
段落、样式、版面布局结构纠缠得很复杂
设计重点偏向输出呈现形式,而不是文本本身
一旦加入表格、图形、表单控件(누름틀)等元素,难度会陡然上升
归根结底,HWP 对人类来说是文档,但从 AI 或代码的角度看,更像是一种难以处理的格式。
最大的问题在于,它与 OOXML、PDF 这类广泛使用的标准化文档流程有相当距离。
2. hwp VS hwpx
或许是意识到了这些局限,最近也开始同时使用 .hwpx 格式。
HWPX 在内部采用基于 XML 的结构。
也就是说,可以像解压 zip 那样打开文件,然后解析其中的 XML。
这个差异比想象中要大。
如果说 HWP 是一团难读的二进制块,那么 HWPX 就更接近于可分析结构的文档。
我自己也利用这一点,把成就标准数据抽取出来,并整理进数据库。
不仅停留在“能读文档”的层面,而是可以作为数据被再利用,从这一点看,HWPX 显然是一个有意义的变化。

3. 用 hwpx + AI 制作公文
顺理成章地就会想到:
如果能用 HWPX 来处理公文,是不是也就能让 AI 来读写这些文档了?
于是我就利用 ChatGPT 和 Claude 让它们实际读取公文,并尝试撰写申请书。
1) 用 ChatGPT 制作公文

ChatGPT 读公文内容的能力相当不错。
摘要和要点整理都相当准确。
但一旦让它帮忙写申请书,往往不是生成完整的文档格式,而是仅以文本的形式输出内容。
用来写初稿已经足够好用,但要直接生成可以提交的正式文档仍有局限。
2) 用 Claude 制作公文
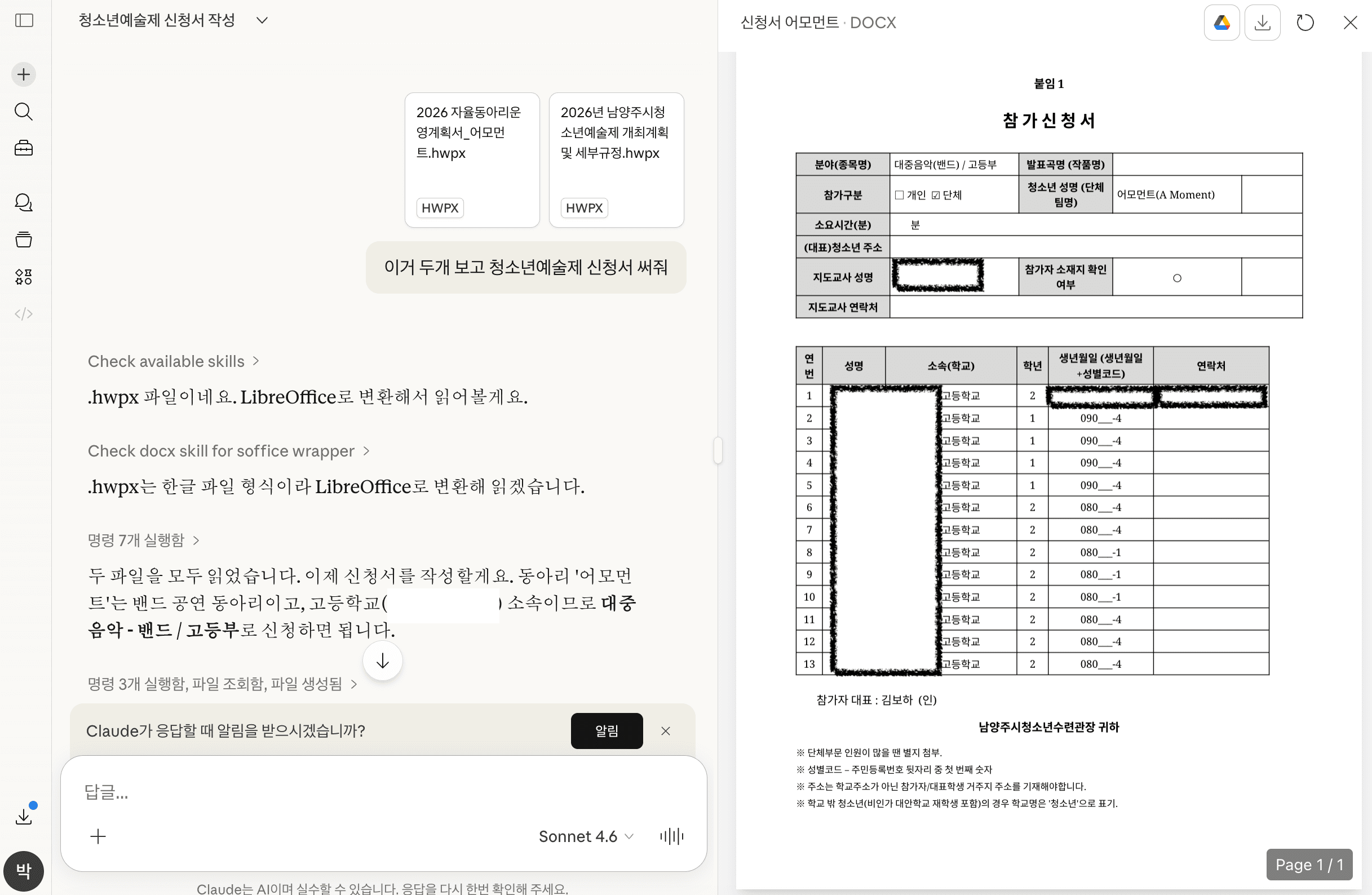
我也用同样的请求试了试 Claude。
这次它能生成 .doc 格式的文档。
格式也相当合适,内容自然流畅。
但最终还是得把结果复制到原来的公文模板中再粘贴一次。
要说是完全自动化,还称不上。
4. 用 kordoc + python-hwpx 制作公文
机缘巧合在 GitHub 上发现了一个用来解析公文的库。
看到它就觉得,借助这个工具,似乎也能在 VS Code 或 Cursor 里编写公文。
因为是基于 node 的,所以我用 npm 进行了安装。
创建了名为 korDoc 的文件夹并在其中安装。
mkdir korDoc
cd korDoc
npm i kordoc
接下来轮到安装 MCP,让 AI 可以调用它。
按 F1,然后搜索 MCP。
然后进入 Tools&MCP,添加自定义 MCP。
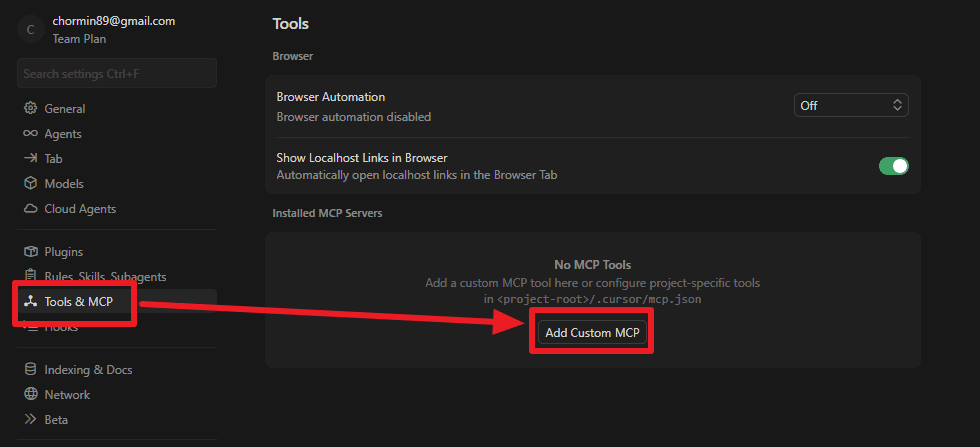
一开始是按照官方文档如下添加 MCP 的。
结果却报错了……?
{
"mcpServers": {
"kordoc": {
"command": "npx",
"args": ["-y", "kordoc-mcp"]
}
}
}2026-04-02 10:37:44.505 [error] npm error 404 'kordoc-mcp@*' is not in this registry.
Error [ERR_MODULE_NOT_FOUND]: Cannot find package 'pdfjs-dist' imported from C:\Users\fecu\AppData\Local\npm-cache\_npx\5ea84d466de2b626\node_modules\kordoc\dist\chunk-VOMMXHNQ.js出现上面的错误后,问了下 AI 大佬,它说因为依赖关系问题,要改成下面这样。
按这样注册之后,就能顺利注册 MCP 了。
{
"mcpServers": {
"kordoc": {
"command": "npx",
"args": ["-y", "-p", "kordoc", "-p", "pdfjs-dist", "kordoc-mcp"]
}
}
}我把韩文文档放进 korDoc,然后让它解析。
在 Cursor 中就能自动读取公文并对内容进行摘要。
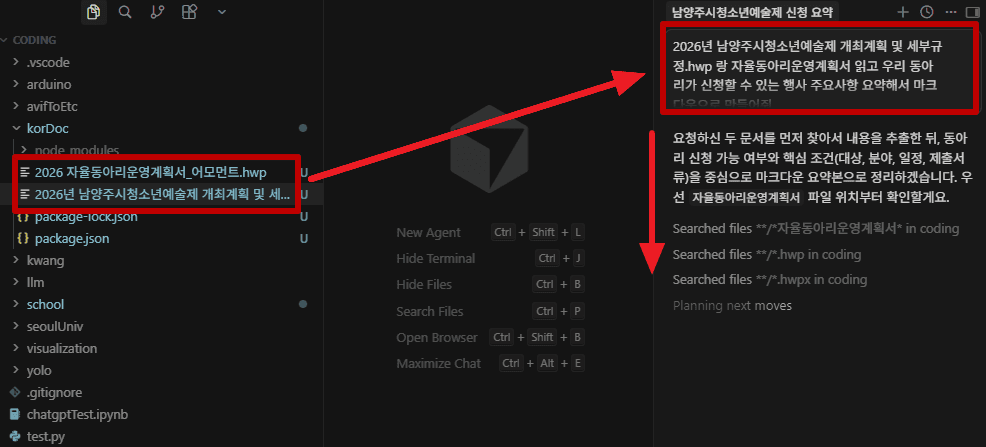

接下来只要让它写申请书就好了……
问题在于,kordoc 本身并不具备生成 hwp、hwpx 的功能。
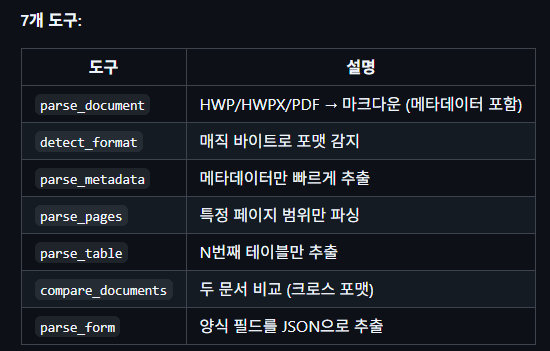
于是我又找到了 python-hwpx。
这是在学校的某位信息老师写好的项目。
利用 hwpx 支持 XML 的特点,把它做成了可生成文档的工具。
它同样支持 MCP,因此我把它和依赖一起安装了。
关于 MCP 的 GitHub 链接放在下面。
pip install uv
pip install python-hwpx跟之前一样,再注册一个自定义 MCP。
{
"mcpServers": {
"hwpx": {
"command": "uv",
"args": ["tool", "run", "hwpx-mcp-server"]
}
}
}然后像下面这样下达命令:
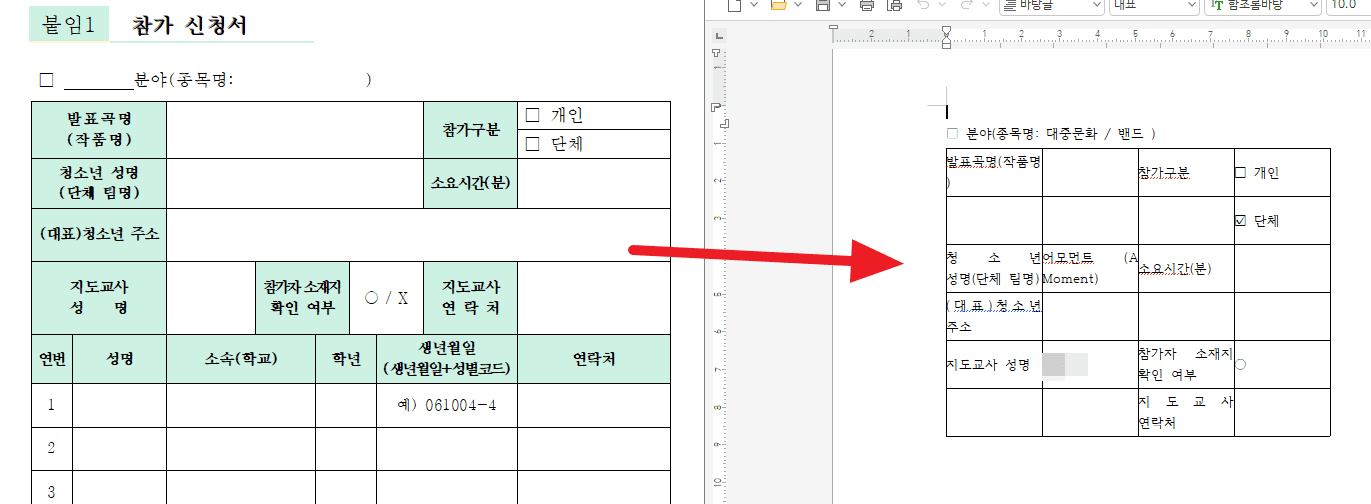
동아리 정보를 바탕으로 신청서 작성해줘.这样一来,它就按下面这样把申请书写好了。
内容已经足以用于正式提交,但格式仍然不算完全符合公文模板。
5. 后记
我尝试用各种 AI 工具和库来处理公文。
随着像 HWPX 这种结构化文档的出现,自动化的可能性的确比过去大得多。
但局限依然非常明显。
基于 HWP 的文档在结构上不利于自动化处理,也不适合作为 AI 稳定理解的格式。
最近在一篇文章里看到这么一句话:“与其指责日本去研发能盖在屏幕上的电子印章,不如反思自身。”
我也深有同感。
是要为了保护国产软件而继续维持这种“加拉帕戈斯”式的生态?
还是要接受基于国际标准的文档体系?
如今,公职社会也到了必须认真思考这个问题的节点。






댓글을 불러오는 중...