以前は、すでにPythonが使えるのに、わざわざRを学ぶ必要があるのかという疑問があった。
今回の研修を受けながら、研究をする際に必ずしもPythonを使う必要はない、ということに気づいた。
Pythonなら、numpyで線形回帰して、グラフを描いて、P value を求めて……といろいろやらないといけないが、Rなら lm と summary 一発で終わる。
そこで今日は、これまで学んだR実習に関する内容を総復習し、実際のデータを活用して練習用の例を見せようと思う。
1. 例題データ
例題データは、Kaggle に公開されているアメリカの学生の成績データである。
もしKaggleに登録していない人のために、下にリンクを貼っておく。
このデータは、保護者の背景や試験対策コースなどが学生の成績に与える影響を見るために作られたものだという。
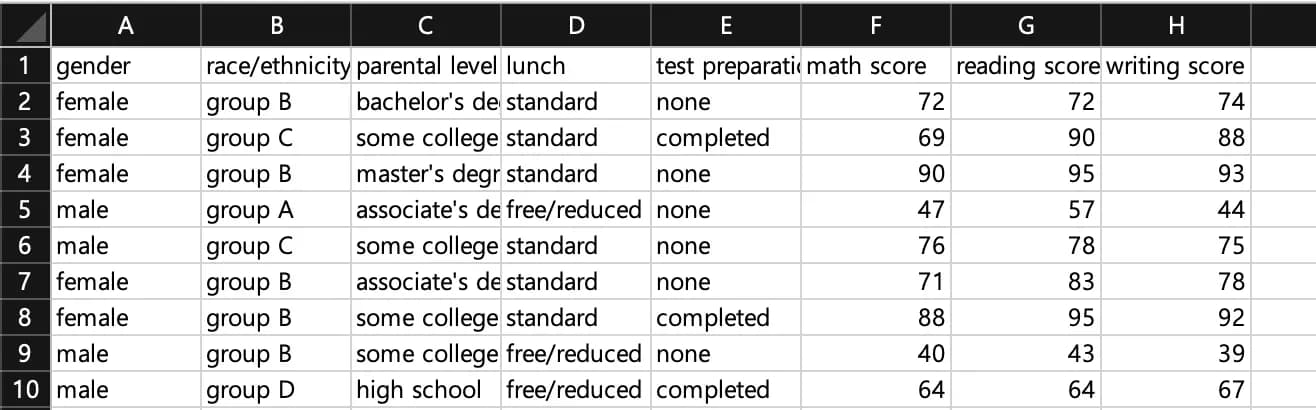
下にデータ内部の値を貼り付けておいた。
簡単に説明すると、gender は学生の性別、race は人種、parental level は保護者の学歴、lunch は給食の価格、test preparation は試験対策コースの受講有無である。
2. R studioでcsvファイルを開く
R studioでファイルを読み込むコマンドは read である。
ファイルパスを入力するのが面倒なら、ファイルをクリックした状態でコピーして貼り付ければ、パスがそのまま入る。
あるいは file.choose() コマンドを使って、Windowsのウィンドウから選ぶこともできる。
ちなみに、各行のコマンド実行は ctrl + enter(Macでは cmd + enter)を押せばよい。
data <- read.csv("파일경로")
// dat <- read.csv(file.choose())
head(data)
3. 線形回帰分析
では、このデータで簡単な線形回帰をしてみよう。
lm という関数は、内部パラメータとして lm(従属変数 ~ 独立変数, データシート) を順番に受け取る。
例えば数学の点数と英語(writing)点数の相関関係を見てみるとしたら、次のように実行すればよい。
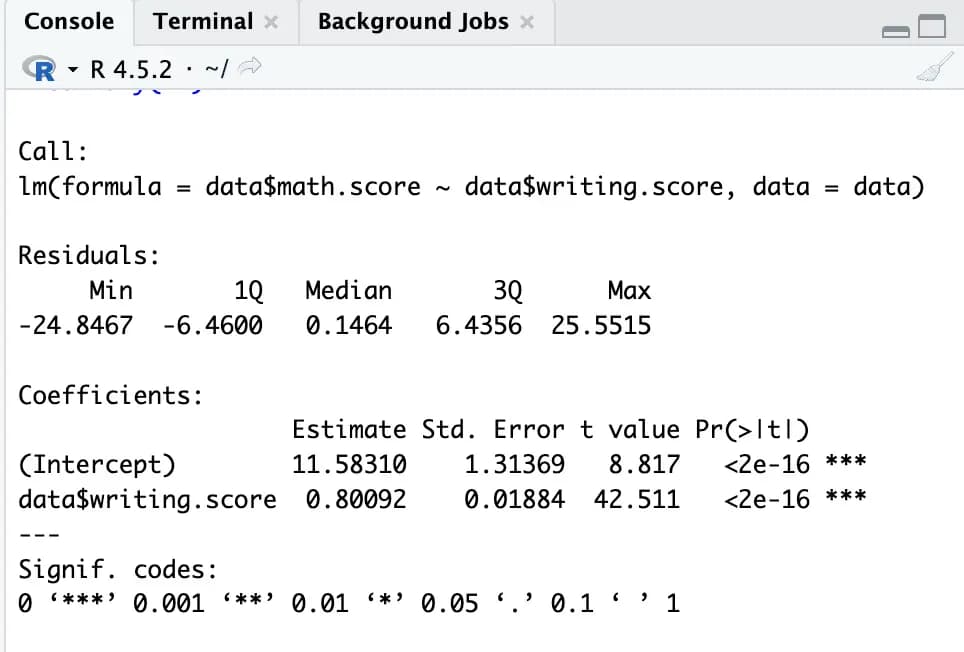
m1 <- lm(data$math.score ~ data$writing.score, data)
summary(m1)これだけで本当に簡単に線形回帰分析が終わる。
誤差、t-test、p-value まで、何も設定しなくても論文に載せられる程度の値が出てくるので、とても便利だ。
4. チャートを描く
グラフも本当に簡単に描くことができる。
単純に plot(m1) と入力するだけで、必要なチャートの大半を描いてくれる。
別に見たいデータがあれば、x軸の値とy軸の値を順番にカンマで区切って入れればよい。
5. 重回帰分析
変数が多いときは、lm の独立変数パラメータの位置に、すべての値を + で区切って入れる。
例えば、writing の点数に対して reading の点数と math の点数の影響を見たいなら、次のように分析できる。
m2 <- lm(data$writing.score ~ data$reading.score + data$math.score, data)
summary(m2)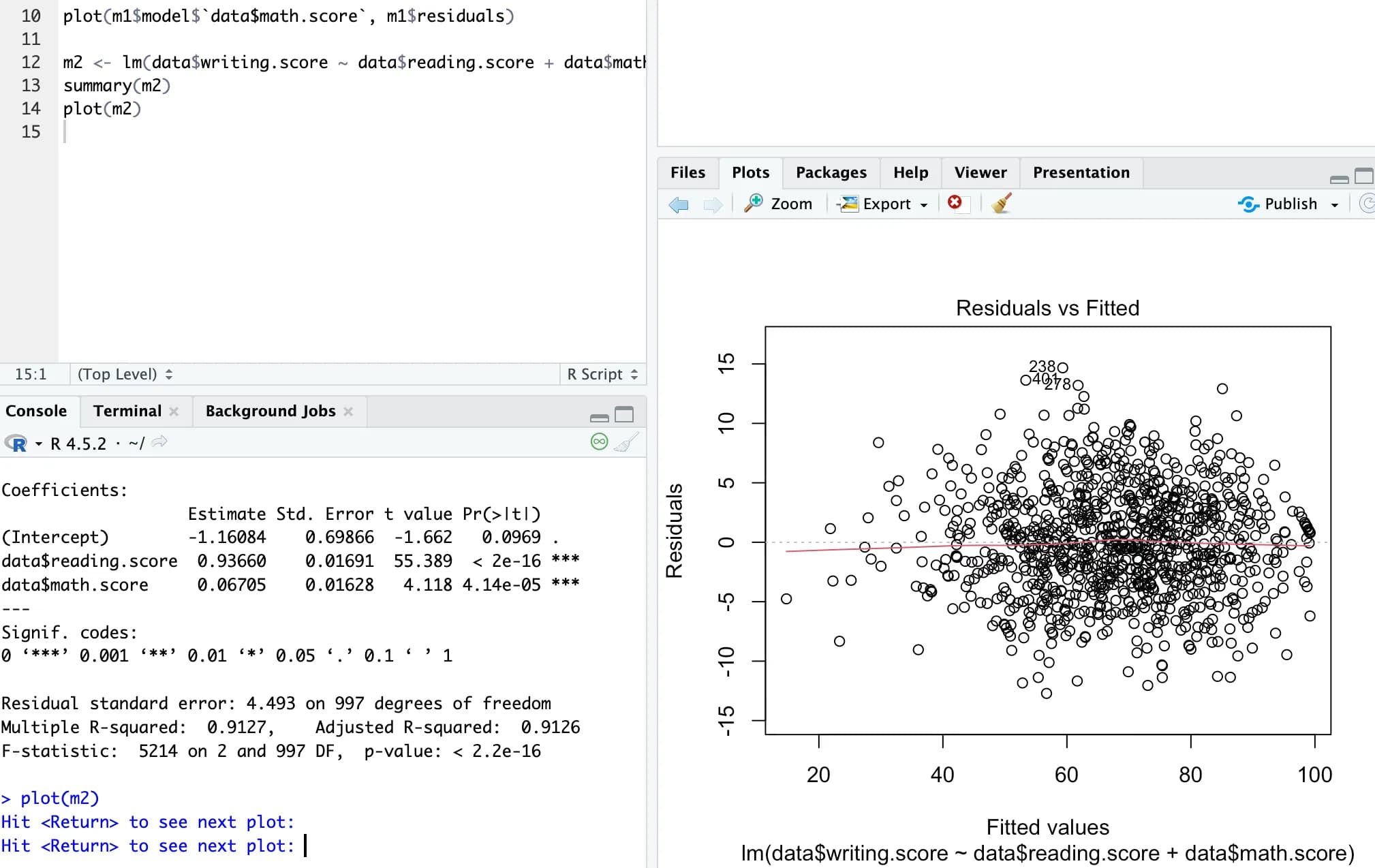
6. カテゴリ変数の処理(数値でないデータの処理)
カテゴリ変数とは、データを質的なグループやカテゴリーに分ける変数のことである。
これは、性別や学歴といった数値ではないデータを処理するためのものである。
ここでは、最も簡単な性別を処理してみよう。
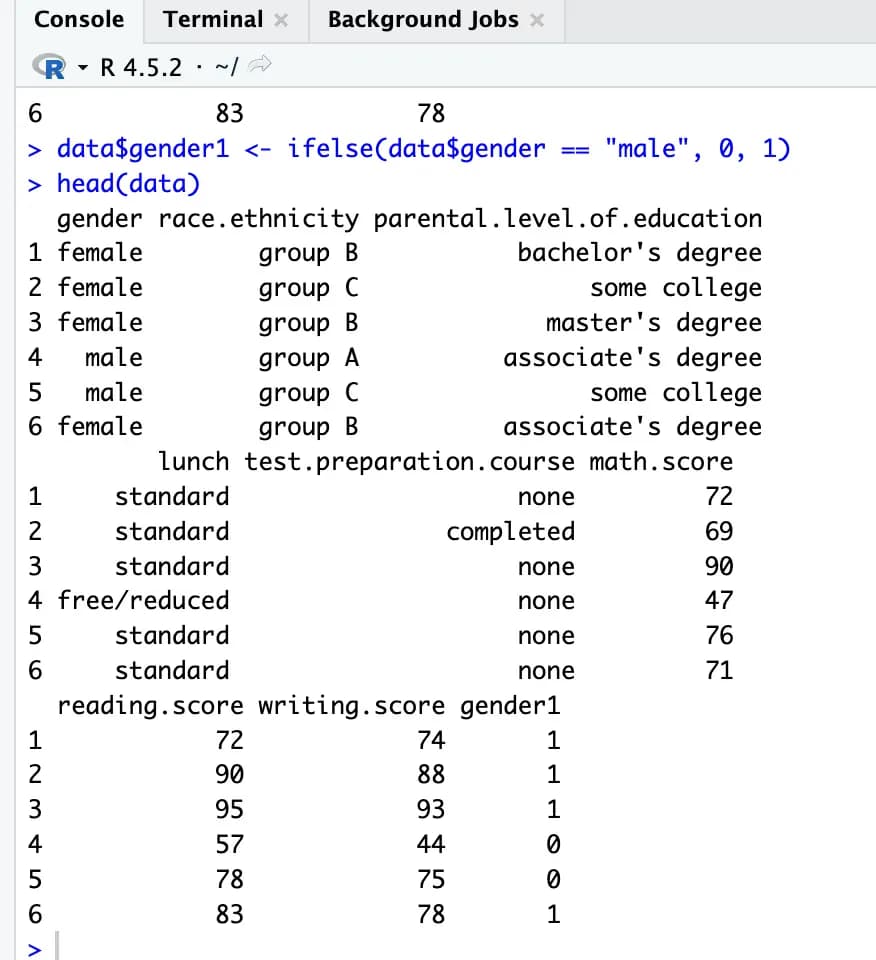
ifelse() 関数を使って、ダミーデータである gender1 を data に追加する。
data$gender1 <- ifelse(data$gender == "male", 0, 1)
// 첫번째 조건이 참일경우 0, 거짓일 경우 1을 입력
head(data)このようにしたあとテーブルを確認すると、gender1 テーブルが新たに作成され、女性の場合は 1、男性の場合は 0 が入っていることがわかる。
これを利用して線形回帰分析を行うこともできる。
ところがおもしろいことに、わざわざこうしなくても、gender をそのまま入れても分析できる。
m3 <- lm(data$math.score ~ data$gender, data)
plot(m3)これは、Rが上で自分たちがやったのと同じように、文字型データを処理してから分析しているためである。

性別は2つだけなので簡単だが、保護者の学歴やグループのように項目が多い場合は少し話が違う。
もし n 個の項目があるなら、n-1 個のダミー変数がさらに必要になる。
自分で作ることもできるが、いっそRに魂を預けてしまうのも悪くない気がする。
m4 <- lm(data$math.score ~ data$race.ethnicity, data)
summary(m4)
plot(m4)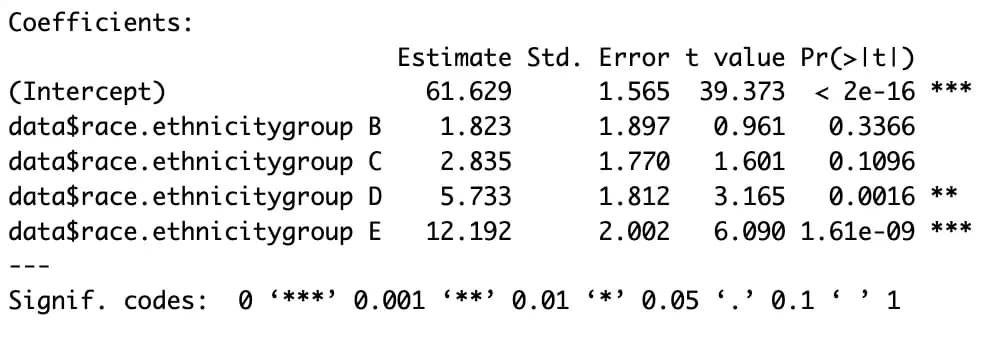
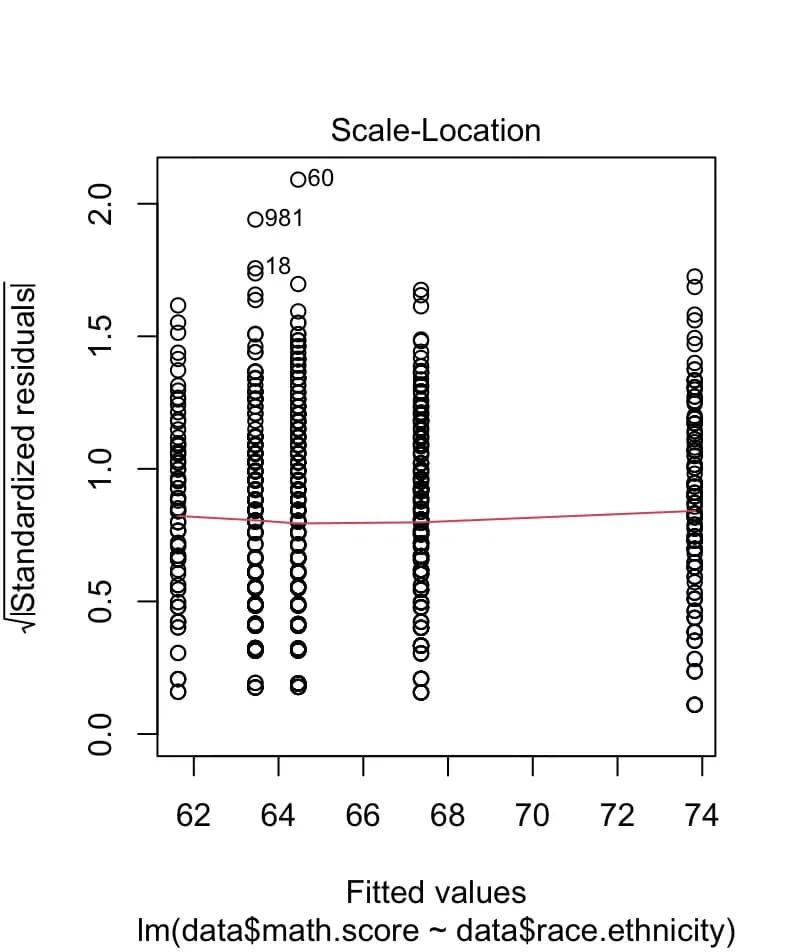
7. resid を用いた残差計算と活用
resid を使うと、線形回帰曲線に対する各項の残差を計算することができる。
残差を活用して、データが線形的かどうか、分散がどのようになっているかを確認できる。
まずデータを分析したあと、変数1つと分析結果を用いて残差を計算し、グラフを描いてみよう。
m5 <- lm(data$math.score ~ data$writing.score, data)
res1 <- resid(m5)
plot(data$writing.score, res1)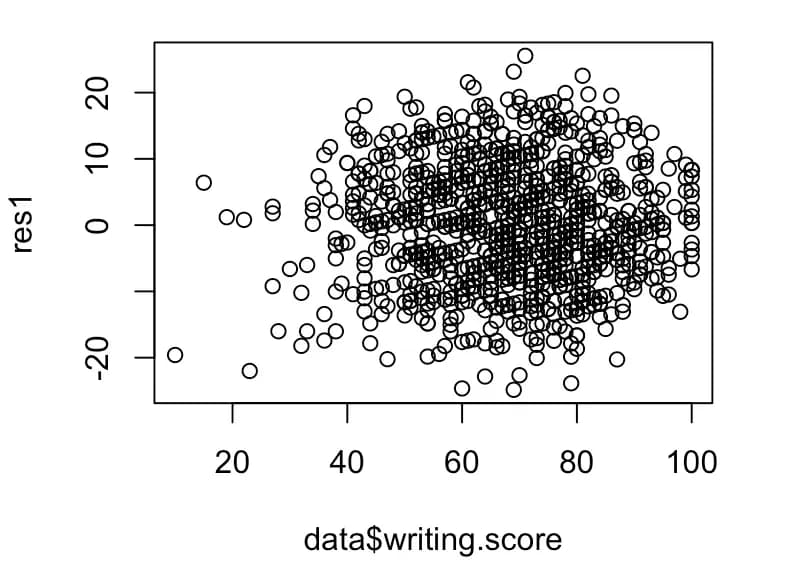
このようにグラフを描いてみると、実際のデータの分散が等分散的ではない。
この場合は、各値に対して軸のスケールを調整してあげる必要がある。
8. Rを用いた交互作用分析 - ステップワイズ回帰分析
ステップワイズ回帰分析は、変数を一つずつ追加しながら影響力を確認するものである。
研究者が一つずつ追加しながら行うこともできるが、Rではこれを自動で全部やってくれる。
m7 <- lm(data$math.score ~ ., data)
m8 <- step(m7, direction = "both")
summary(m8)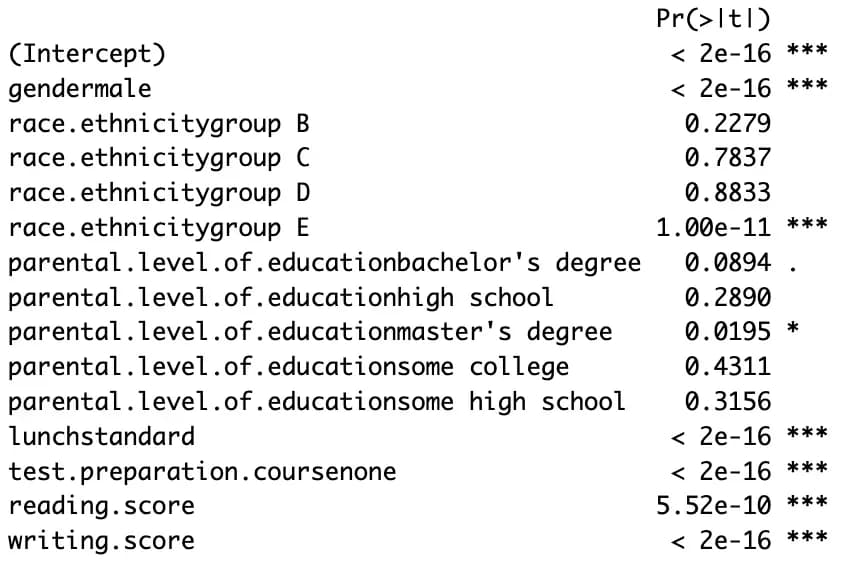
この方法は簡単だが、解釈が難解である。
そのため、研究者の意図に沿って分析する階層的回帰分析の方が好まれるとのことだ。
9. 感想
ステップワイズ回帰分析をぶち込んで、一番よく説明できるモデルを選んで、p-value が一番低い方向で結論を出せばいいんじゃないかと思っていたが、そうではなかった。
Rは便利ではあるが、結論を得るためには研究者の思考プロセスがとても重要だと感じた。
勉強する前は、Rを学ばなくてもPythonで全部解決できると思っていたが、大きな勘違いだった。
私はRを崇拝するようになった。






댓글을 불러오는 중...