之前我一直有个疑问:既然已经会 Python,真的还有必要再学 R 吗?
这次听完研修之后,我意识到,在做研究的时候其实完全没必要非得用 Python。
用 Python 的话,要用 numpy 做线性回归、画图、算 P value 等等,全都要自己一项项做;但是在 R 里,用 lm 和 summary 一句就可以搞定。
所以今天就把到目前为止学过的 R 实操内容做个总复习,并且用真实数据来展示练习示例。
1. 示例数据
示例数据是 Kaggle 上的美国学生成绩数据。
考虑到有的人可能还没注册 Kaggle,我在下面附上了一个下载链接。
据说这份数据是为了考察父母背景、考试准备课程等因素对学生成绩的影响而制作的。
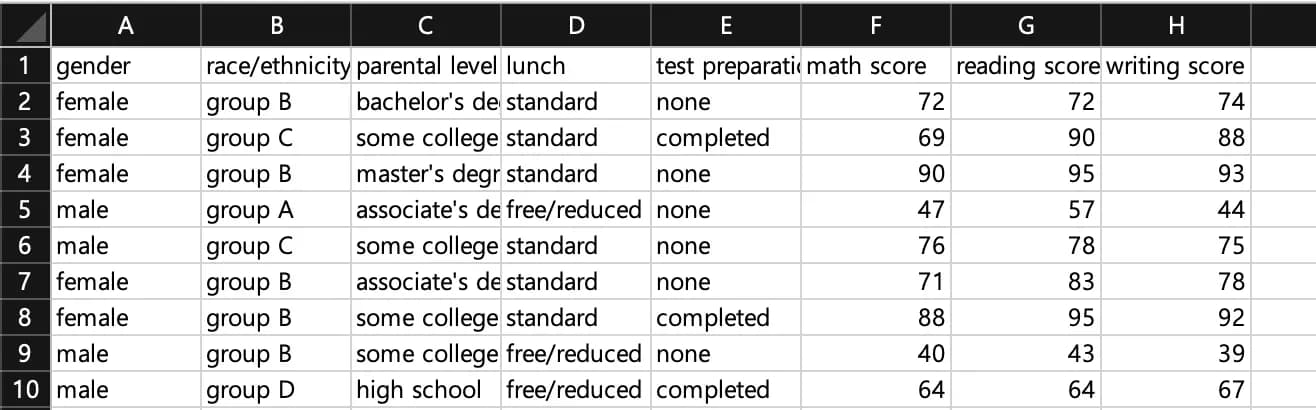
下面贴上了数据内部的字段值。
简单说明一下:gender 是学生性别,race 是种族,parental level 是父母的受教育程度,lunch 是供餐价格,test preparation 是是否完成考试准备课程。
2. 在 R Studio 中打开 csv 文件
在 R Studio 中用来读取文件的命令是 read。
如果嫌输入文件路径麻烦,可以先选中要打开的文件,复制然后粘贴到这里,路径就会自动填入。
或者也可以用 file.choose() 命令,在 Windows 窗口里直接选择文件。
另外,每一行命令的执行可以用 ctrl + enter(Mac 上是 cmd + enter)。
data <- read.csv("文件路径")
// dat <- read.csv(file.choose())
head(data)
3. 线性回归分析
现在用这份数据做一个简单的线性回归。
lm 这个函数的内部参数依次为 lm(因变量 ~ 自变量, 数据表)。
比如要看数学成绩和写作成绩之间的相关关系,可以像下面这样运行:
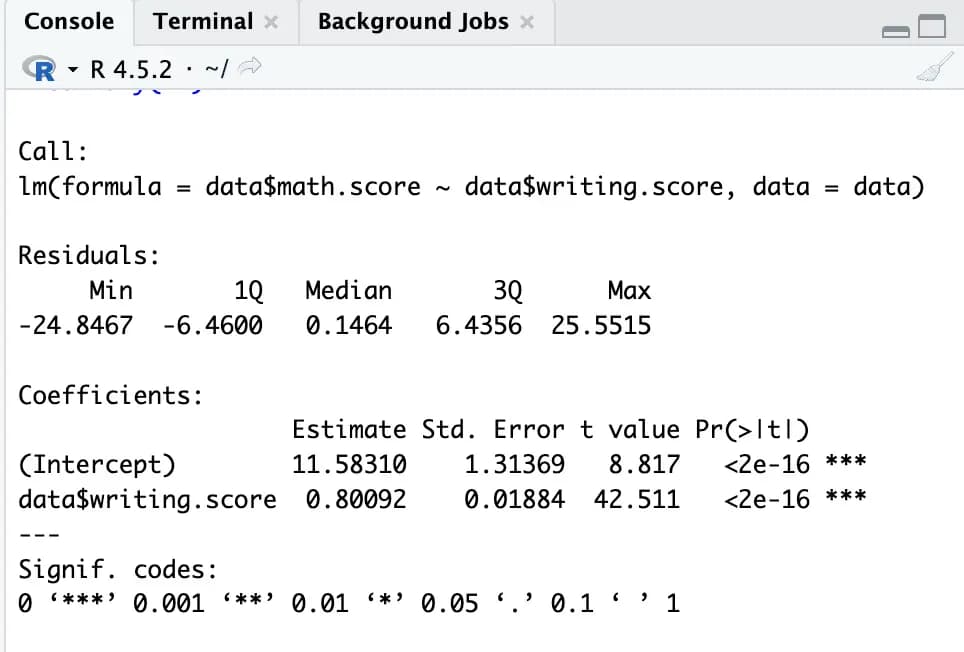
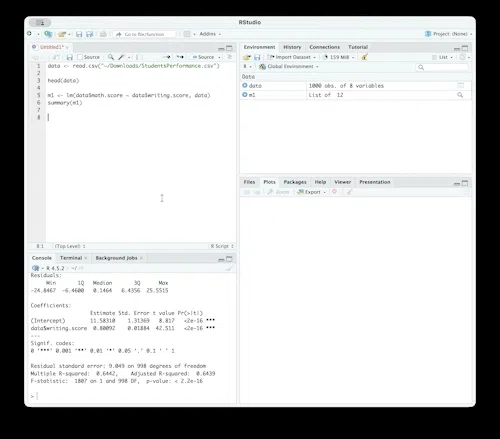
m1 <- lm(data$math.score ~ data$writing.score, data)
summary(m1)这样就非常简单地完成了线性回归分析。
误差、t 检验、p-value 等等,即使什么都不额外设置,也会给出可以直接写进论文的结果,非常方便。
4. 绘制图表
画图也可以非常轻松地完成。
只要简单输入 plot(m1),大部分需要的图表就会自动绘制出来。
如果有想单独查看的数据,只要依次输入 x 轴和 y 轴的值,并用逗号分隔即可。
5. 多元回归分析
当自变量很多时,只要在 lm 的自变量参数位置把所有变量用 + 号连接起来就行。
例如想看阅读成绩和数学成绩对写作成绩的影响,可以按下面这样分析:
m2 <- lm(data$writing.score ~ data$reading.score + data$math.score, data)
summary(m2)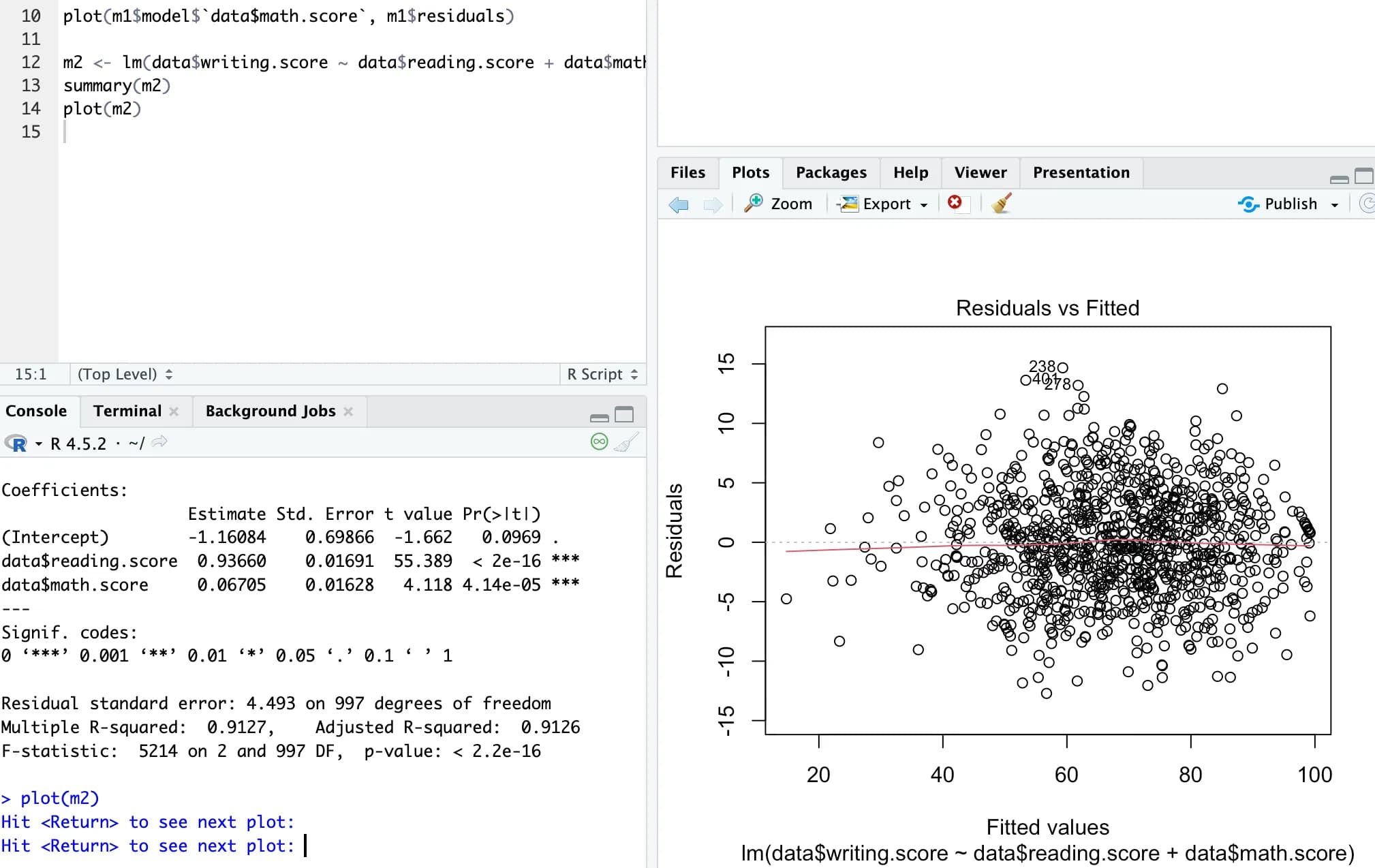
6. 类别变量处理(非数值数据的处理)
类别变量是指把数据划分为若干质性组或类别的变量。
这是为了处理像性别、学历这类非数值型数据。
这里先用最简单的性别来演示。
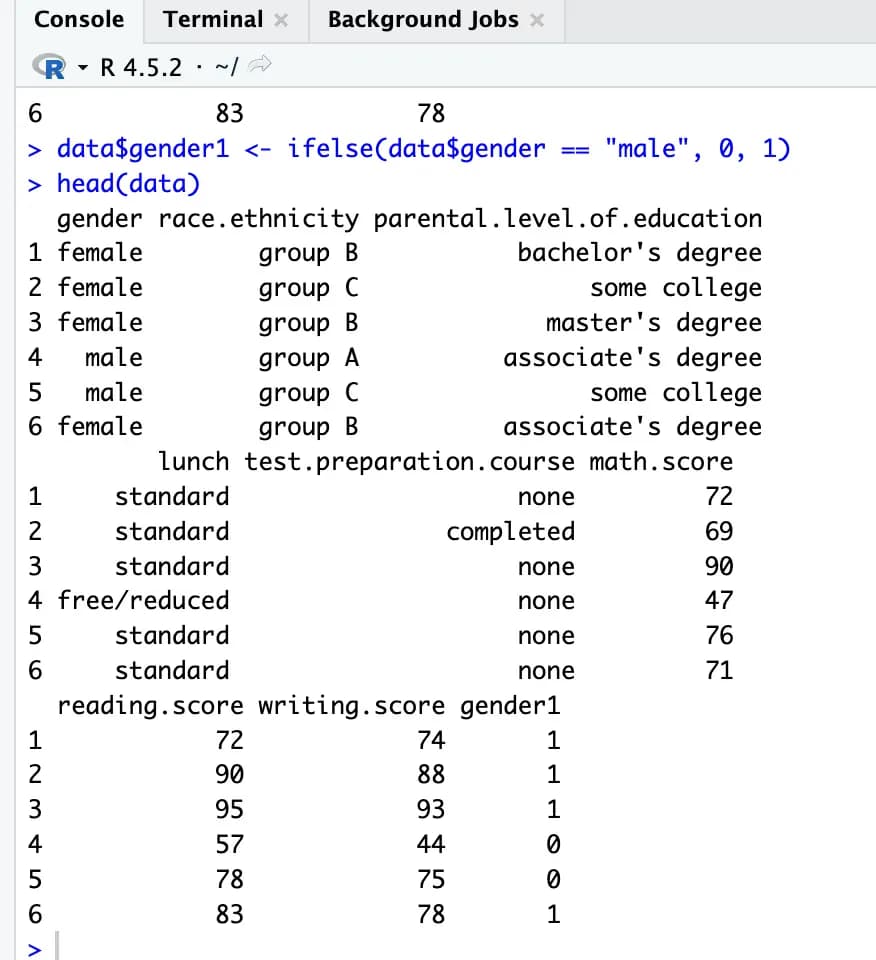
利用 ifelse() 函数,往 data 中加入一个名为 gender1 的虚拟变量。
data$gender1 <- ifelse(data$gender == "male", 0, 1)
// 第一条条件为真时赋值 0,为假时赋值 1
head(data)这样之后再查看表格,就会发现新增了 gender1 这一列,女性为 1,男性为 0。
现在就可以利用它来做线性回归分析了。
有趣的是,其实就算不做这些处理,直接把 gender 丢进去也可以完成分析。
m3 <- lm(data$math.score ~ data$gender, data)
plot(m3)这是因为 R 会像我们上面那样,自动先处理字符型数据,然后再进行分析。

性别只有两个类别,所以相对简单;但是像父母学历或分组这种包含多个类别的变量情况就有点不一样了。
如果有 n 个类别,就需要 n-1 个虚拟变量。
虽然也可以手动创建,但直接把灵魂托付给 R 似乎也未尝不可。
m4 <- lm(data$math.score ~ data$race.ethnicity, data)
summary(m4)
plot(m4)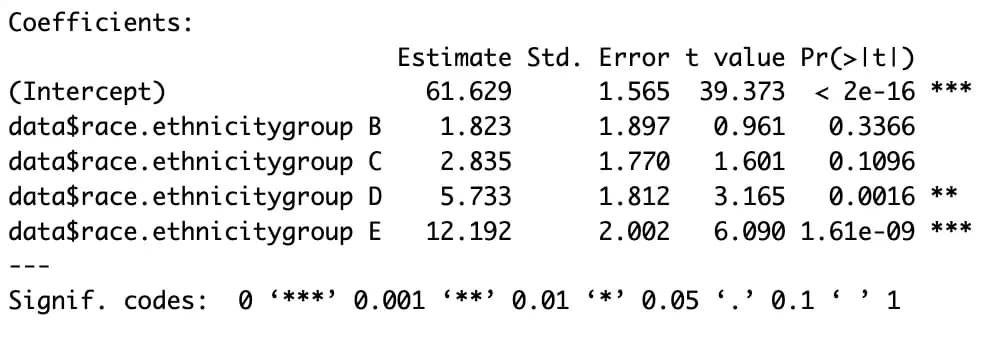
7. 利用 resid 计算并使用残差
通过 resid 可以计算每一项相对于线性回归曲线的残差。
利用残差可以检查数据是否呈线性、方差状况如何。
先进行数据分析,然后用一个自变量和分析结果来计算残差并绘制图形。
m5 <- lm(data$math.score ~ data$writing.score, data)
res1 <- resid(m5)
plot(data$writing.score, res1)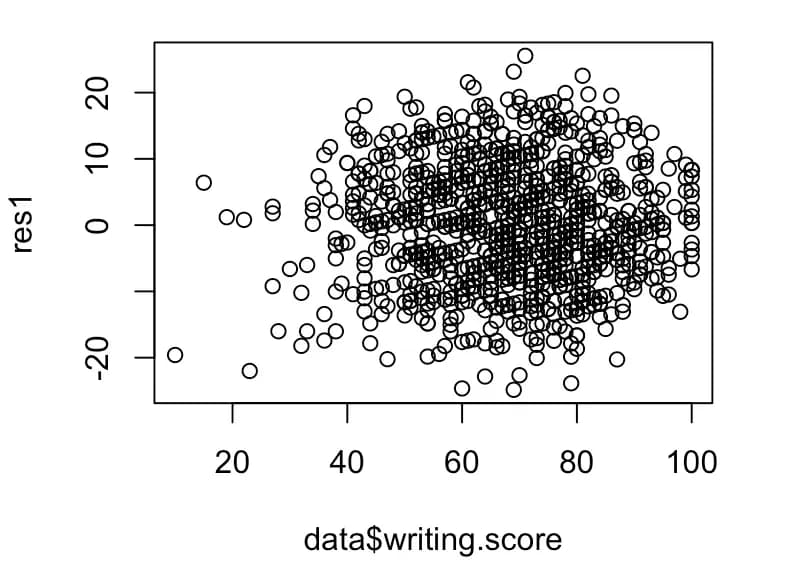
画出图之后可以看到,实际数据的方差并不是等方差的。
这种情况下,就需要对各个数值的轴尺度进行调整。
8. 利用 R 进行交互作用分析——逐步回归分析
逐步回归分析是指逐个加入变量,检查其影响力的过程。
研究者当然可以手动逐个加入变量,但在 R 中这些都能自动完成。
m7 <- lm(data$math.score ~ ., data)
m8 <- step(m7, direction = "both")
summary(m8)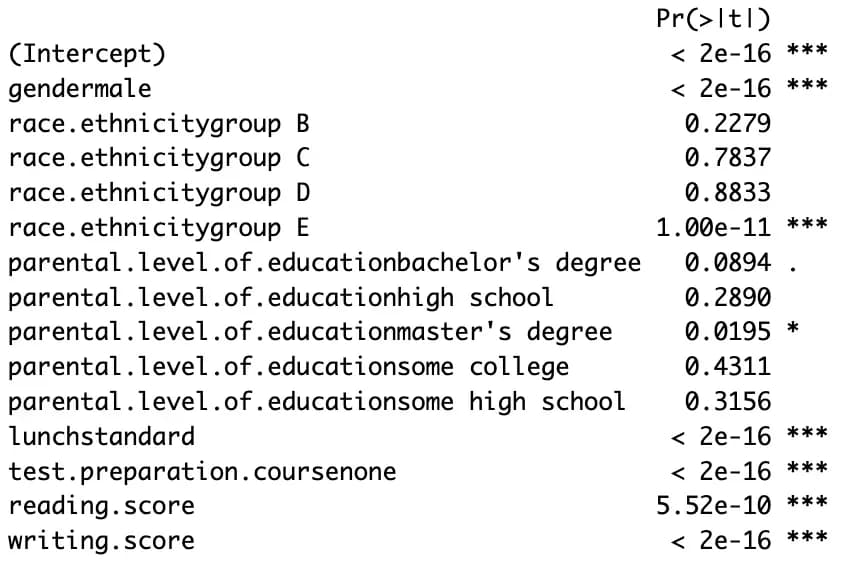
这种方法虽然简单,但结果的解读会比较困难。
因此据说大家更偏好能根据研究者意图来分析的层级回归分析。
9. 后记
我原本以为随便做个逐步回归,选一个解释力最强的模型,然后沿着 p-value 最低的方向下结论就行了,结果发现并不是这么回事。
R 的确很好用,但为了得到结论,研究者的思考过程仍然非常重要。
在学习之前,我一直觉得不用学 R,用 Python 就能解决一切,事实证明这是天大的误解。
如今,我开始膜拜 R 了。






댓글을 불러오는 중...