大韓民国の公共機関では今でも .hwp 拡張子のファイルが多く使われている。
このファイルはハングルとコンピュータ社が作った独自規格の文書だ。
問題は、この形式が他のプログラムと完全には互換性がないという点にある。
文書を開いて中身を見ること自体は可能だ。
しかし、その内容を構造的に読み取り、データとして活用するのは全く別の問題だ。
そしてまさにこの点が、公文書をAIで処理しようとするとき最大の障害になる。
1. 公文書パースが難しい理由 - hwp
HWPは単なる文書ファイルではない。
ハングル専用のバイナリフォーマットなので、人間が目で読むことと機械が構造的に解釈することは全く別物だ。
ファイルを開いて中身を見ること自体はできるかもしれない。
しかし、段落・表・項目・書式といった意味単位で安定してパースすることははるかに難しい。
理由は単純だ。
段落・スタイル・レイアウト構造が複雑に絡み合っており
テキストそのものより出力形態を中心に設計されていて
表・図形・押しボタン(フォーム)などの要素が入ると難易度が急激に上がる
結局HWPは、人間から見れば文書だが、AIやコードの立場からすると扱いにくいフォーマットに近い。
最大の問題は、OOXMLやPDFのように広く使われている標準ベースの文書フローとは距離があるという点だ。
2. hwp VS hwpx
こうした限界を意識してか、最近は .hwpx 形式も併用されている。
HWPXは内部的にXMLベースの構造を採用している。
つまり、ファイルをzipのように展開し、XMLをパースする方式で扱うことができる。
この違いは思った以上に大きい。
HWPが読みづらいバイナリの塊だとすれば、HWPXは構造を解析できる文書に近い。
私もこの点を活用して、成就基準データを抽出し、データベースとして整理してみたことがある。
文書を単に読むレベルを超えてデータとして再利用できるという点で、HWPXは確かに意味のある変化だ。

3. hwpx + AIで公文書を作る
そうなると自然にこんな考えが浮かぶ。
公文書をHWPXとして扱えるなら、AIで読んだり書いたりすることもできるのでは?
そこでChatGPTとClaudeを使って、実際に公文書を読ませ、申請書を作成させてみた。
1) ChatGPTで公文書を作る

ChatGPTは公文書の内容をかなりよく読んでくれる。
要約やポイントの整理もかなり正確だ。
しかし申請書を作成してほしいと頼むと、完成した文書という形ではなく、内容だけをテキストとして出力する場合が多い。
ドラフトを作るには十分有用だが、そのまま提出できる文書を作るには限界がある。
2) Claudeで公文書を作る
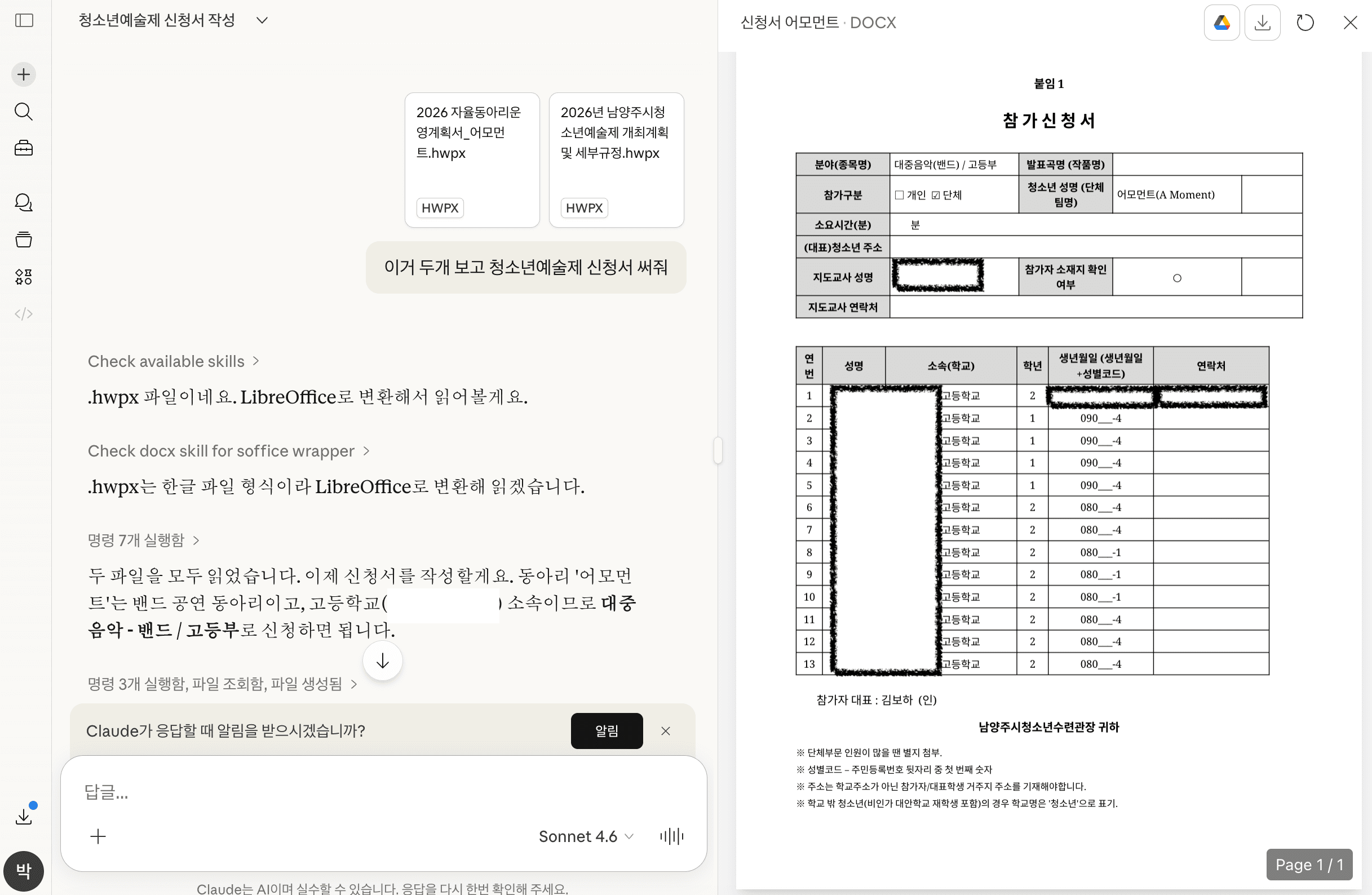
Claudeにも同じように依頼してみた。
今度は .doc 形式の文書を生成してくれる。
様式もかなりきちんとしていて、内容も自然だ。
しかし結局、結果をコピーして既存の公文書フォーマットに貼り付け直さなければならない。
依然として完全な自動化とは言い難い。
4. kordoc + python-hwpxで公文書を作る
ひょんなことから、GitHubで公文書をパースするライブラリを一つ見つけた。
これを使えば、VS CodeやCursorでも公文書を作成できそうだと思った。
nodeベースなのでnpmを使ってインストールした。
korDocというフォルダを作成してインストールした。
mkdir korDoc
cd korDoc
npm i kordoc
次はAIが利用できるようにMCPをインストールする番だ。
F1を押してMCPを検索する。
そしてTools&MCPに入り、カスタムMCPを追加した。
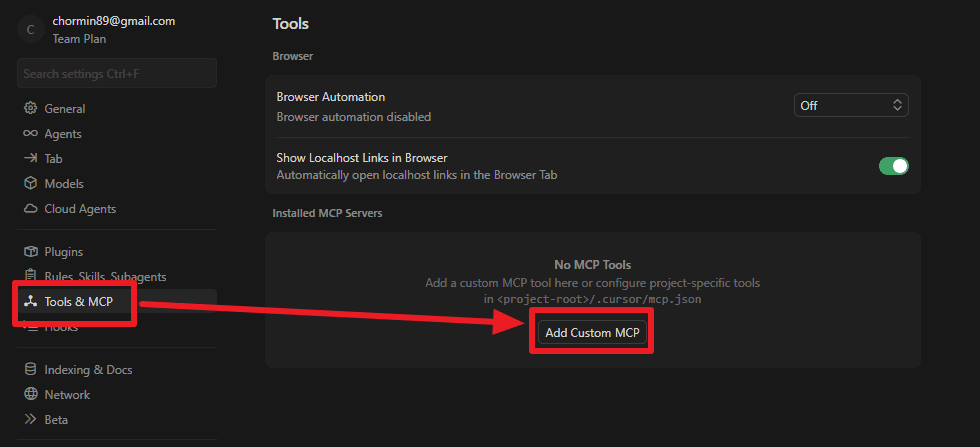
最初は公式ドキュメント通り、下記のようにMCPを追加した。
ところがエラーが…?
{
"mcpServers": {
"kordoc": {
"command": "npx",
"args": ["-y", "kordoc-mcp"]
}
}
}2026-04-02 10:37:44.505 [error] npm error 404 'kordoc-mcp@*' is not in this registry.
Error [ERR_MODULE_NOT_FOUND]: Cannot find package 'pdfjs-dist' imported from C:\Users\fecu\AppData\Local\npm-cache\_npx\5ea84d466de2b626\node_modules\kordoc\dist\chunk-VOMMXHNQ.js上のようなエラーが出たので、AI兄さんに聞いてみたところ、依存関係のせいだから下のように変えるようにと言われた。
このように登録すると、MCPをスムーズに登録できた。
{
"mcpServers": {
"kordoc": {
"command": "npx",
"args": ["-y", "-p", "kordoc", "-p", "pdfjs-dist", "kordoc-mcp"]
}
}
}korDocにハングル文書を入れてパースさせてみた。
Cursorから自動的に公文書を読み込み、その内容を要約してくれた。
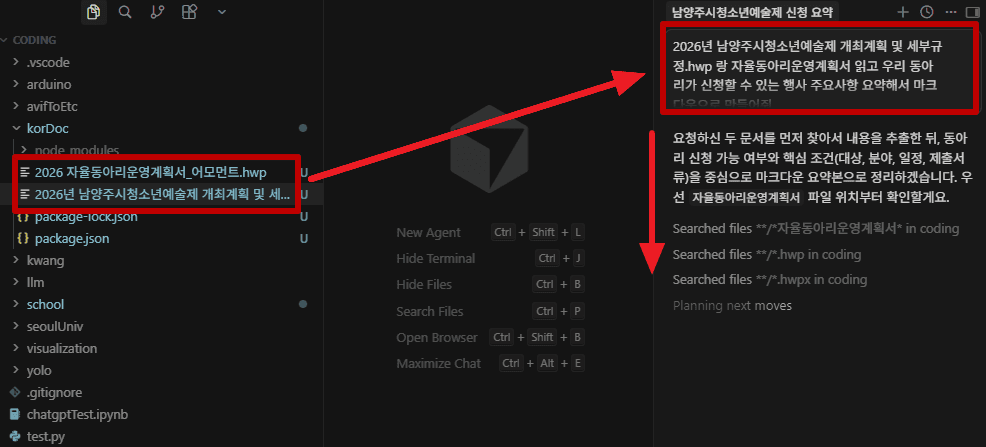

あとは申請書を作成するよう指示するだけなのだが…
問題は、kordocにはhwp, hwpxを作成する機能がないことだ。
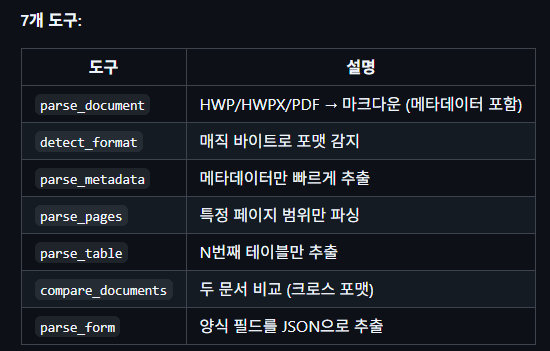
そこで次に見つけたのがpython-hwpxだ。
これは学校にいらっしゃる情報科の先生が作ってくださったものだ。
hwpxがXMLをサポートしている点を活用し、文書を生成できるように作られている。
これもMCPをサポートしているので、依存関係と合わせてインストールする。
MCPについてのGitHubリンクは下に貼っておく。
pip install uv
pip install python-hwpx先ほどと同様に、カスタムMCPを登録する。
{
"mcpServers": {
"hwpx": {
"command": "uv",
"args": ["tool", "run", "hwpx-mcp-server"]
}
}
}そして下のようなコマンドを出してみた。
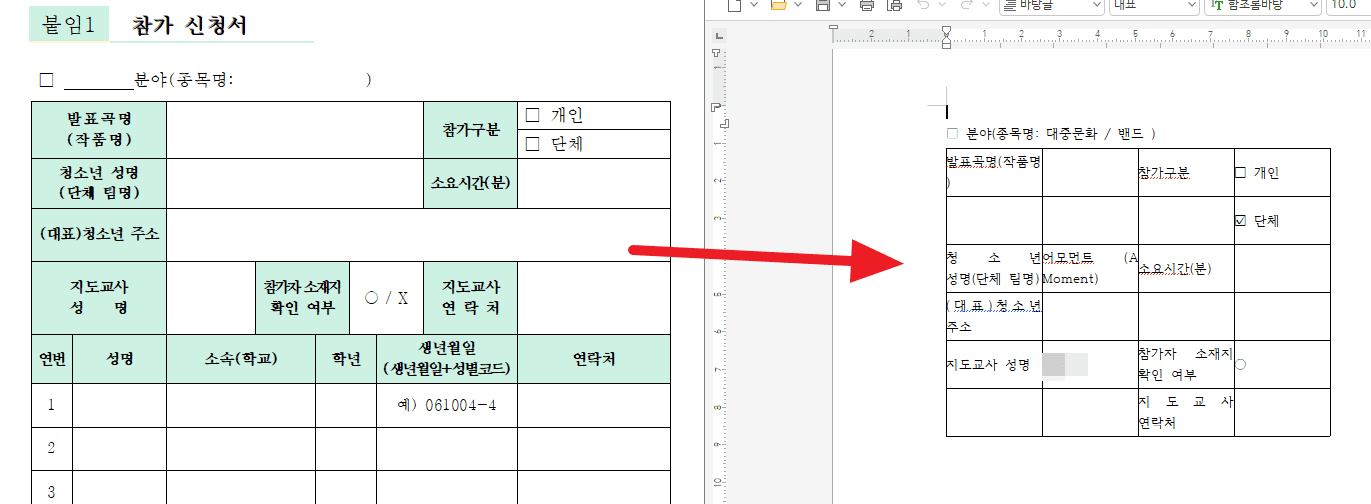
동아리 정보를 바탕으로 신청서 작성해줘.するとこのように申請書を作成してくれた。
内容は提出できる程度には充実しているが、依然として様式は整っていない状態だ。
5. 感想
さまざまなAIツールとライブラリを活用して公文書を扱ってみた。
HWPXのような構造化された文書が登場したことで、確かに自動化の可能性は以前より高まった。
しかしそれでも限界ははっきりしている。
HWPベースの文書は構造的に自動化に不利であり、AIが安定して理解するのにも適していないフォーマットだ。
最近ある文章で、「スクリーンに押せるハンコを開発した日本を笑うべきではない」という言葉を目にしたことがある。
私もこれに共感している。
国産ソフトウェアを守るために、ガラパゴスのような生態系をこのまま維持し続けるのか?
それとも国際標準ベースの文書体系を受け入れるのか?
いまや公務員社会も、この問題を真剣に考えるべき時期に来ている。






댓글을 불러오는 중...