Antes me preguntaba si realmente hacía falta aprender R cuando ya sabía usar Python.
Al seguir este curso de formación, me di cuenta de que, a la hora de investigar, no es realmente necesario usar Python.
En Python, con numpy hay que hacer la regresión lineal, dibujar los gráficos, calcular el valor p, etc., pero en R todo termina de una vez con lm y summary.
Así que hoy voy a repasar de forma general todo lo que hemos aprendido hasta ahora en las prácticas con R y mostrar algunos ejemplos de ejercicios usando datos reales.
1. Datos de ejemplo
Los datos de ejemplo son un conjunto de datos de calificaciones de estudiantes estadounidenses publicado en Kaggle.
Para quienes no estén registrados en Kaggle, dejo el enlace más abajo.
Según se indica, estos datos se crearon para analizar la influencia sobre el rendimiento académico del alumnado de factores como el trasfondo familiar, la realización de un curso de preparación para exámenes, etc.
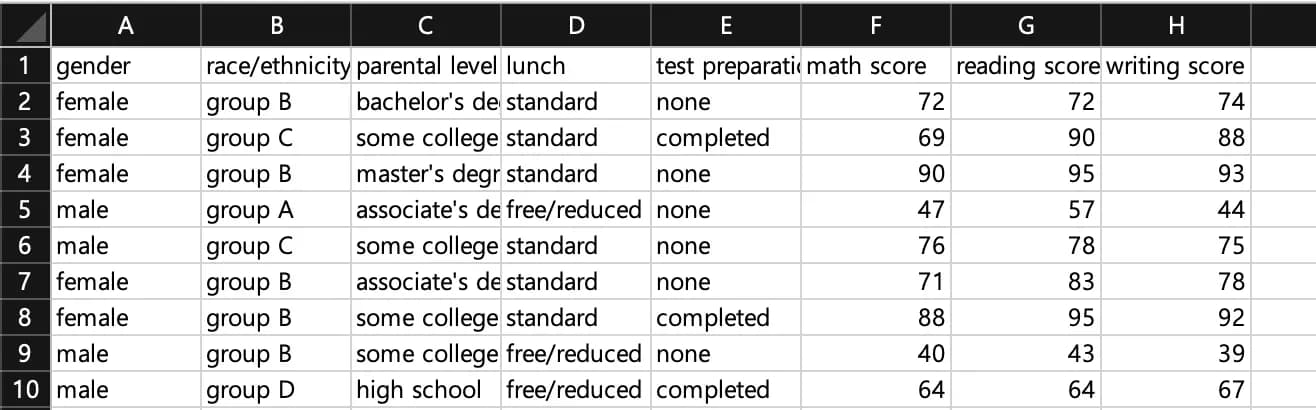
He pegado a continuación los valores internos de los datos.
Explicándolo de forma sencilla: gender es el sexo del estudiante, race la raza, parental level el nivel educativo de los padres, lunch el precio del almuerzo escolar y test preparation indica si ha completado o no un curso de preparación para exámenes.
2. Abrir un archivo csv en R Studio
El comando para cargar archivos en R Studio es read.
Si te da pereza introducir la ruta del archivo, basta con copiar el archivo haciendo clic sobre él y luego pegar: la ruta se insertará automáticamente.
O puedes usar el comando file.choose() y seleccionar el archivo desde la ventana de Windows.
Por cierto, para ejecutar cada línea de comando, hay que usar ctrl + enter (cmd + enter en Mac).
data <- read.csv("파일경로")
// dat <- read.csv(file.choose())
head(data)
3. Análisis de regresión lineal
Ahora probemos una regresión lineal sencilla con estos datos.
La función lm recibe como parámetros internos, en este orden, lm(variable dependiente ~ variable independiente, hoja de datos).
Por ejemplo, si queremos ver la relación entre la nota de matemáticas y la de inglés, podemos ejecutar lo siguiente:
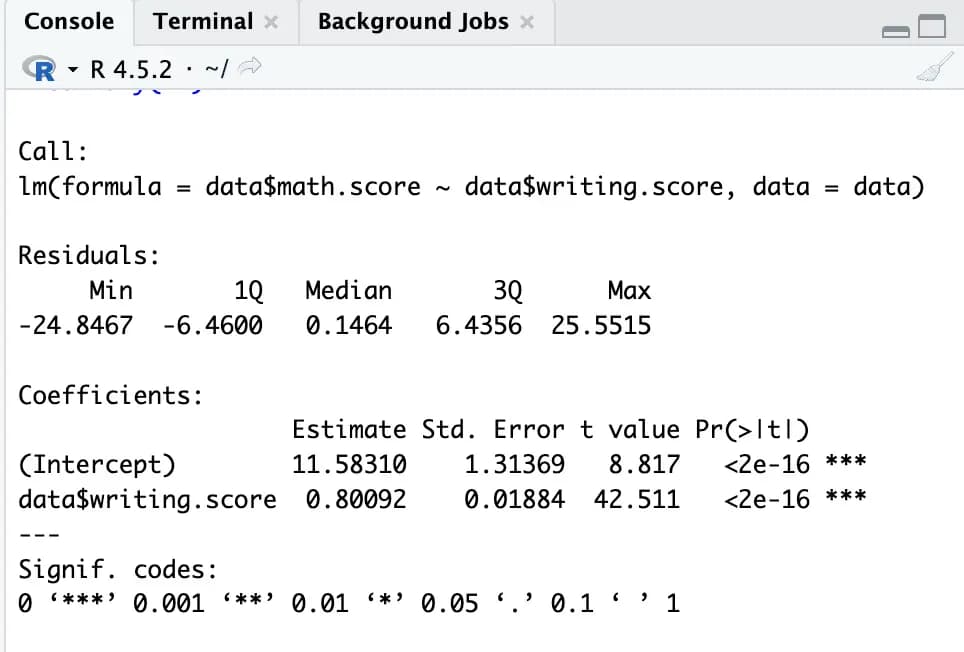
m1 <- lm(data$math.score ~ data$writing.score, data)
summary(m1)Con esto, el análisis de regresión lineal queda resuelto de forma muy sencilla.
Sin necesidad de configurar nada, se obtienen valores como errores, prueba t, p-value, etc., con una calidad suficiente para incluirlos en un artículo, lo cual es muy cómodo.
4. Trazar gráficos
Los gráficos también se pueden dibujar de forma muy sencilla.
Con solo introducir plot(m1) se generan la mayoría de los gráficos necesarios.
Si quieres trabajar con datos concretos, basta con introducir los valores del eje x y del eje y en ese orden, separados por comas.
5. Análisis de regresión múltiple
Cuando hay muchas variables, en la posición del parámetro de variables independientes de lm se introducen todas las variables separadas con +.
Por ejemplo, si queremos ver el efecto de la nota de lectura y la de matemáticas sobre la nota de escritura, podemos analizarlo así:
m2 <- lm(data$writing.score ~ data$reading.score + data$math.score, data)
summary(m2)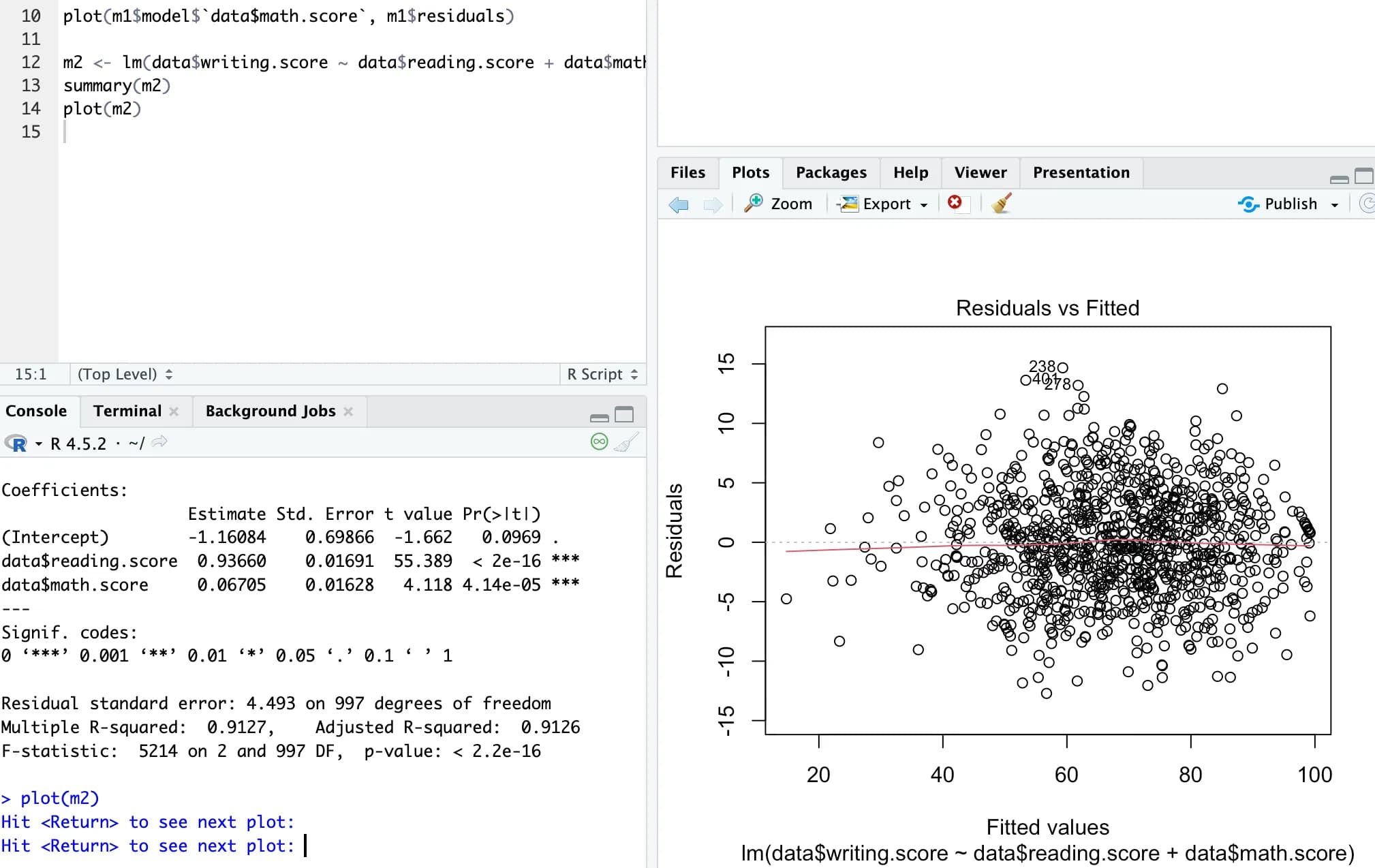
6. Tratamiento de variables categóricas (datos no numéricos)
Las variables categóricas son variables que dividen los datos en grupos o categorías cualitativas.
Se utilizan para tratar datos no numéricos como el sexo, el nivel educativo, etc.
Aquí vamos a trabajar con el ejemplo más sencillo: el sexo.
Usamos la función ifelse() para inyectar en data la variable ficticia gender1.
data$gender1 <- ifelse(data$gender == "male", 0, 1)
// 첫번째 조건이 참일경우 0, 거짓일 경우 1을 입력
head(data)Después de esto, si comprobamos la tabla, veremos que se ha creado una nueva columna gender1 y que tiene el valor 1 para las mujeres y 0 para los hombres.
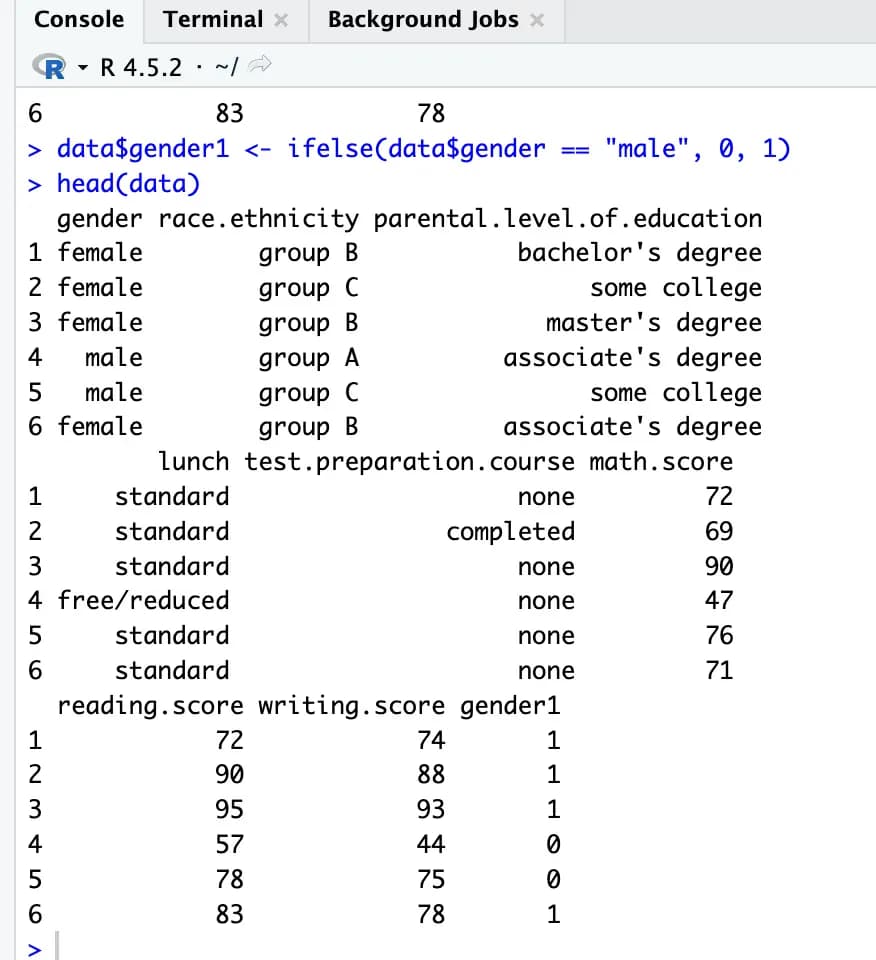
Ahora podemos usar esto para hacer un análisis de regresión lineal.
Lo curioso es que, aunque no hagamos todo este proceso, la regresión también funciona si metemos directamente gender.
m3 <- lm(data$math.score ~ data$gender, data)
plot(m3)Esto se debe a que R trata las variables de tipo carácter como hicimos arriba y después realiza el análisis.

Con el sexo es fácil porque solo hay dos categorías, pero cuando se trata del nivel educativo de los padres o de grupos con varios ítems, la cosa cambia un poco.
Si hay n categorías, se necesitan n-1 variables ficticias adicionales.
Se pueden crear a mano, pero no parece mala idea dejarle el alma a R y que él se encargue.
m4 <- lm(data$math.score ~ data$race.ethnicity, data)
summary(m4)
plot(m4)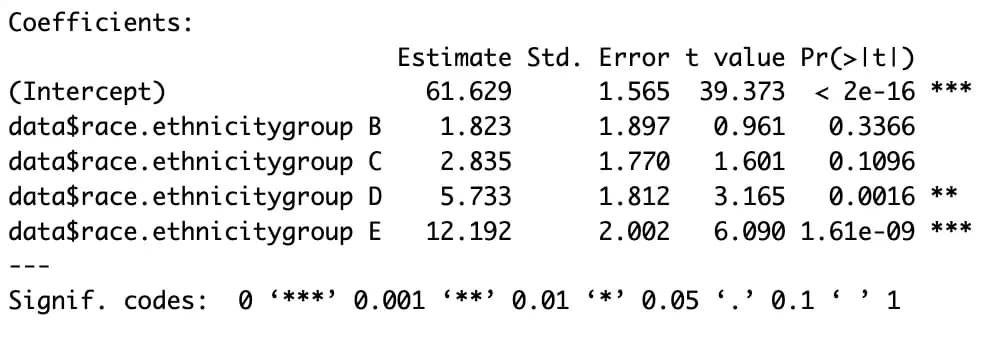
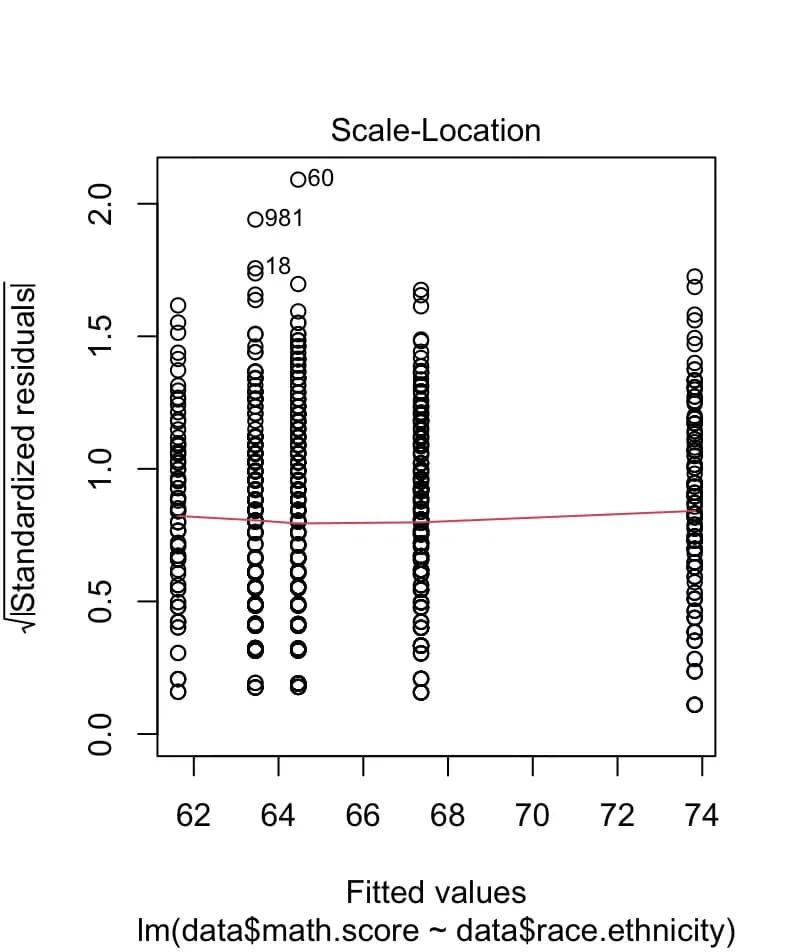
7. Cálculo y uso de los residuos con resid
Con resid se pueden calcular los residuos de cada término respecto a la curva de regresión lineal.
Usando los residuos podemos comprobar si los datos son lineales y cómo es la varianza.
Primero analizamos los datos y, usando una variable y el resultado del análisis, calculamos los residuos y trazamos el gráfico.
m5 <- lm(data$math.score ~ data$writing.score, data)
res1 <- resid(m5)
plot(data$writing.score, res1)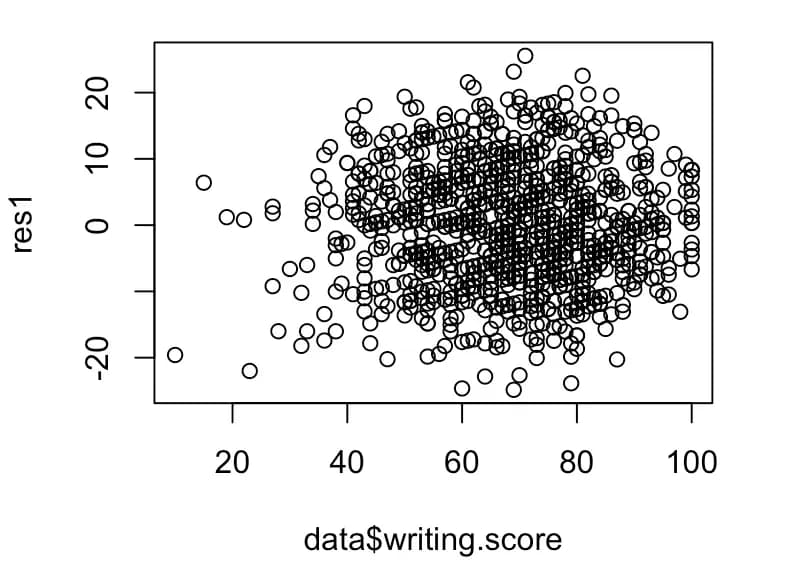
Al dibujar el gráfico de esta forma, vemos que la varianza de los datos reales no es homocedástica.
En estos casos, hay que ajustar la escala del eje para cada valor.
8. Análisis de interacciones con R - Regresión paso a paso
El análisis de regresión paso a paso consiste en ir añadiendo variables una a una y comprobar su influencia.
El investigador puede hacerlo manualmente, pero en R todo este proceso se puede automatizar.
m7 <- lm(data$math.score ~ ., data)
m8 <- step(m7, direction = "both")
summary(m8)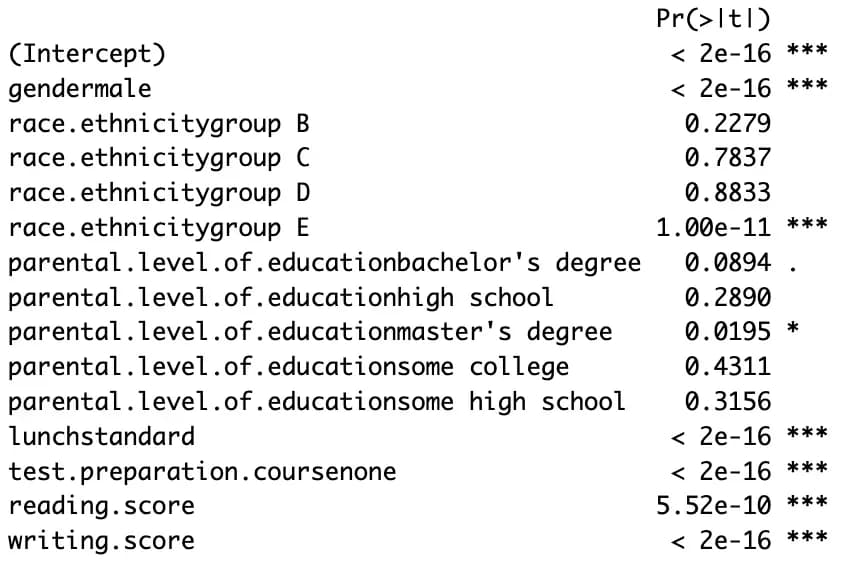
Este método es sencillo, pero su interpretación es complicada.
Por eso se dice que se prefiere más el análisis de regresión jerárquica, que se lleva a cabo según la intención del investigador.
9. Comentarios finales
Yo pensaba que bastaba con meter una regresión paso a paso, elegir el modelo que mejor explicara los datos y luego sacar conclusiones en la dirección del p-value más bajo, pero no era así.
Aunque R es muy cómodo, me di cuenta de que el proceso de pensamiento del investigador es fundamental para llegar a conclusiones.
Antes de estudiar, pensaba que podía resolverlo todo con Python sin aprender R, pero estaba muy equivocado.
He acabado por alabar a R.






댓글을 불러오는 중...