En los organismos públicos de la República de Corea se siguen usando muchos archivos con la extensión .hwp.
Este archivo es un formato de documento propietario creado por Hancom.
El problema es que este formato no es completamente compatible con otros programas.
Es posible abrir el documento para verlo.
Pero leer su contenido de forma estructurada y utilizarlo como si fuera un dato es un asunto totalmente distinto.
Y justo en este punto se convierte en el mayor obstáculo cuando se intenta procesar documentos públicos con IA.
1. Por qué es difícil hacer el parsing de documentos oficiales – hwp
HWP no es un simple archivo de documento.
Es un formato binario exclusivo para coreano, de modo que lo que la persona ve con sus ojos y lo que la máquina interpreta estructuralmente son problemas completamente distintos.
Abrir el archivo para echarle un vistazo puede ser posible.
Pero parsear de forma estable en unidades con significado como párrafos, tablas, ítems o formatos es mucho más difícil.
La razón es sencilla.
Las estructuras de párrafo, estilo y diseño están enredadas de forma compleja, y
está diseñado centrándose más en la forma de salida que en el propio texto, y
cuando entran elementos como tablas, formas o campos de formulario, la dificultad aumenta drásticamente
Al final, aunque HWP es un documento para las personas, para la IA o el código es un formato difícil de manejar.
El mayor problema es que está lejos del flujo de documentos basados en estándares ampliamente utilizados como OOXML o PDF.
2. hwp VS hwpx
Quizá siendo conscientes de estas limitaciones, últimamente también se utiliza el formato .hwpx.
HWPX utiliza internamente una estructura basada en XML.
Es decir, se puede abordar abriendo el archivo como si fuera un zip y parseando el XML.
Esta diferencia es mayor de lo que parece.
Si HWP es un bloque binario difícil de leer, HWPX se acerca a un documento cuya estructura se puede analizar.
Yo mismo aproveché este punto para extraer datos de criterios de logro y organizarlos en una base de datos.
En el sentido de que permite reutilizar el documento como dato, y no limitarse simplemente a leerlo, HWPX es sin duda un cambio significativo.

3. Crear documentos oficiales con hwpx + IA
Entonces, de forma natural, surge esta idea.
Si se puede manejar un documento oficial como HWPX, ¿no sería posible leerlo y escribirlo con IA?
Así que, utilizando ChatGPT y Claude, probé a hacer que leyeran un documento oficial real y redactaran una solicitud.
1) Crear documentos oficiales con ChatGPT

ChatGPT lee bastante bien el contenido de los documentos oficiales.
Los resúmenes y la organización de los puntos clave son bastante precisos.
Pero cuando se le pide que redacte una solicitud, a menudo solo devuelve el contenido en texto y no en forma de documento terminado.
Es suficientemente útil para elaborar un borrador, pero tiene limitaciones a la hora de crear un documento listo para presentar.
2) Crear documentos oficiales con Claude
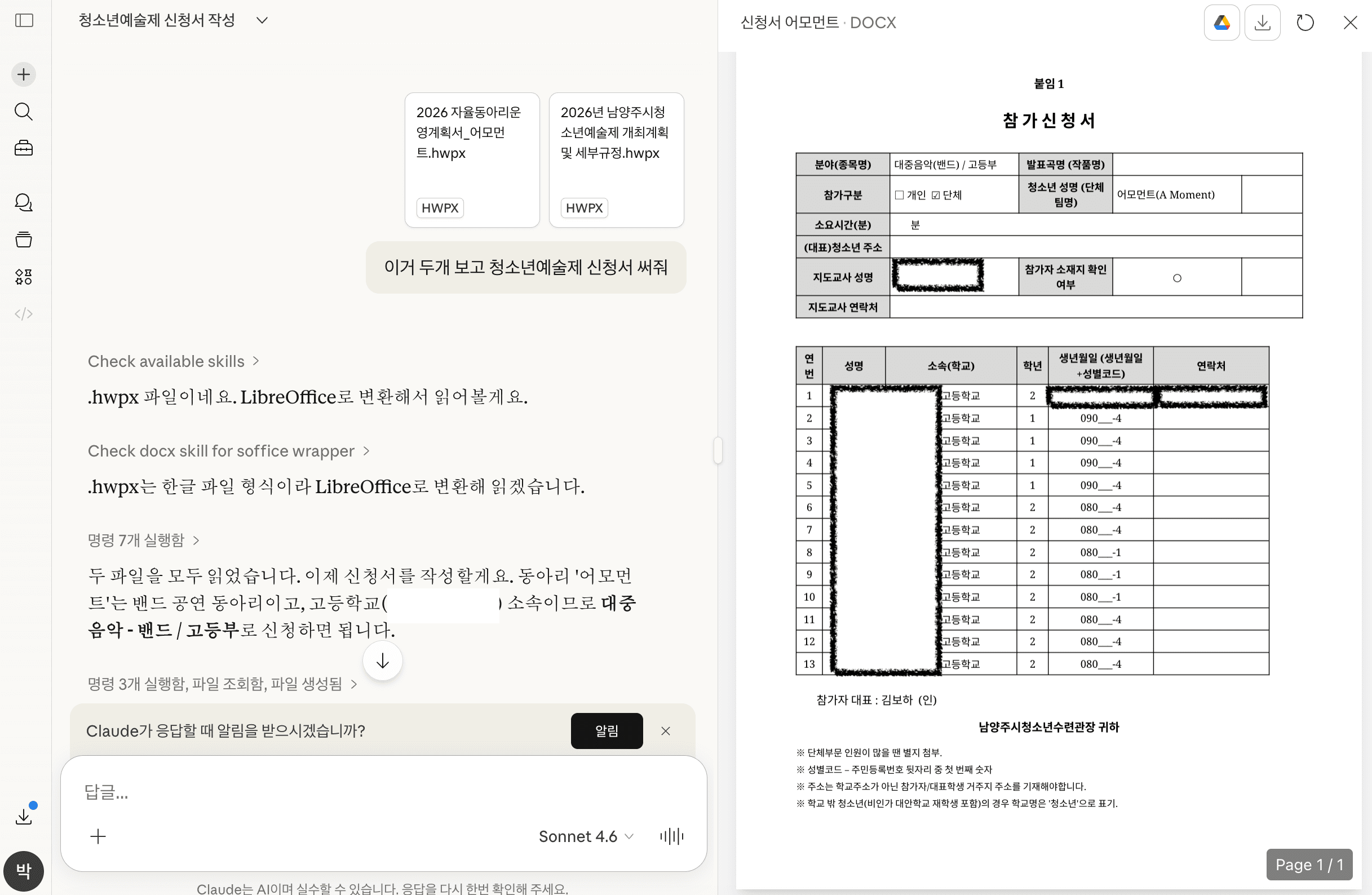
Le hice la misma petición a Claude.
Esta vez genera un documento en formato .doc.
Se ajusta bastante bien al formulario y el contenido es natural.
Pero al final hay que copiar el resultado y pegarlo de nuevo en el formulario oficial existente.
Sigue siendo difícil considerarlo una automatización completa.
4. Crear documentos oficiales con kordoc + python-hwpx
Por casualidad encontré en GitHub una librería que parsea documentos oficiales.
Pensé que, utilizando esto, sería posible redactar documentos oficiales incluso en vscode o cursor.
Como se basa en node, lo instalé con npm.
Creé una carpeta llamada korDoc y lo instalé allí.
mkdir korDoc
cd korDoc
npm i kordoc
Ahora tocaba instalar el MCP para que la IA pudiera usarlo.
Pulsa F1 y busca MCP.
Luego entra en Tools&MCP y añade un MCP personalizado.
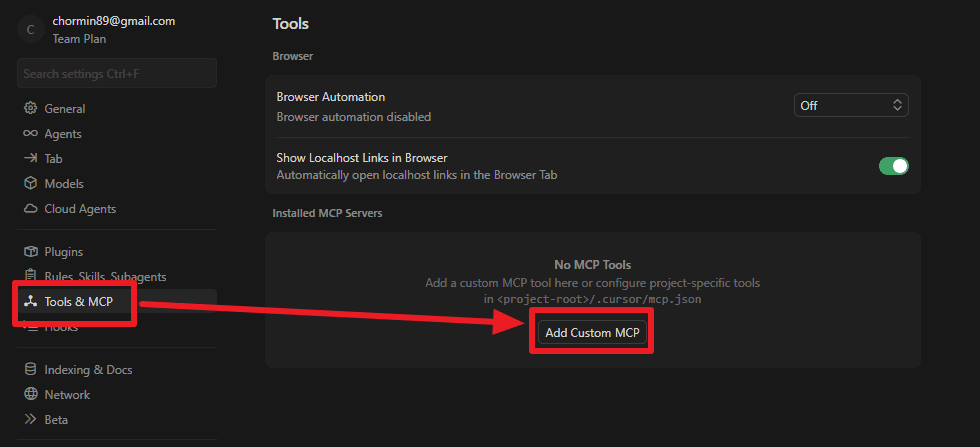
Al principio añadí el MCP de la siguiente forma, tal como indicaba la documentación oficial.
Pero apareció un error....?
{
"mcpServers": {
"kordoc": {
"command": "npx",
"args": ["-y", "kordoc-mcp"]
}
}
}2026-04-02 10:37:44.505 [error] npm error 404 'kordoc-mcp@*' is not in this registry.
Error [ERR_MODULE_NOT_FOUND]: Cannot find package 'pdfjs-dist' imported from C:\Users\fecu\AppData\Local\npm-cache\_npx\5ea84d466de2b626\node_modules\kordoc\dist\chunk-VOMMXHNQ.jsComo aparecía el error de arriba, le pregunté al hermano mayor IA, y me dijo que lo cambiara así por un tema de dependencias.
Al registrarlo de esta manera, pude registrar el MCP sin problemas.
{
"mcpServers": {
"kordoc": {
"command": "npx",
"args": ["-y", "-p", "kordoc", "-p", "pdfjs-dist", "kordoc-mcp"]
}
}
}Puse documentos en coreano en korDoc y probé a parsearlos.
En Cursor, leyó automáticamente el documento oficial y me resumió el contenido.
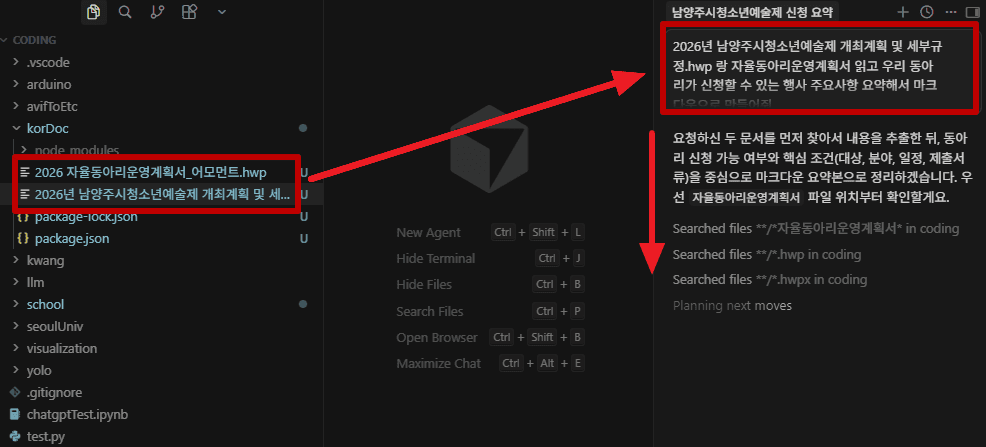

Ahora solo quedaba darle la orden de redactar la solicitud...
El problema es que kordoc no tiene la función de crear hwp o hwpx.
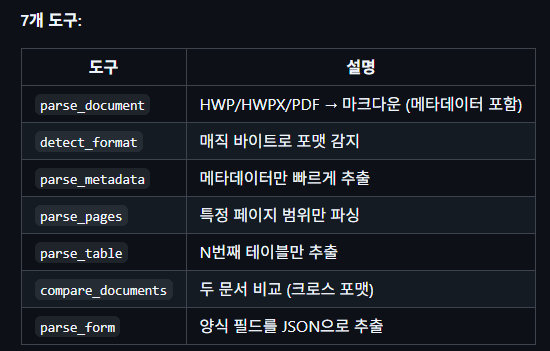
Así que lo siguiente que descubrí fue python-hwpx.
Lo hizo un profesor de informática que trabaja en un centro escolar.
Aprovechando que hwpx admite xml, lo creó para poder generar documentos.
Este también admite MCP, así que lo instalé junto con sus dependencias.
Dejo abajo el enlace de GitHub relativo al MCP.
pip install uv
pip install python-hwpxIgual que antes, registré un MCP personalizado.
{
"mcpServers": {
"hwpx": {
"command": "uv",
"args": ["tool", "run", "hwpx-mcp-server"]
}
}
}Y lancé una orden como la de abajo.
동아리 정보를 바탕으로 신청서 작성해줘.Al hacerlo, redactó la solicitud como se ve a continuación.
El contenido es suficientemente sólido como para presentarlo, pero aún no respeta el formato.
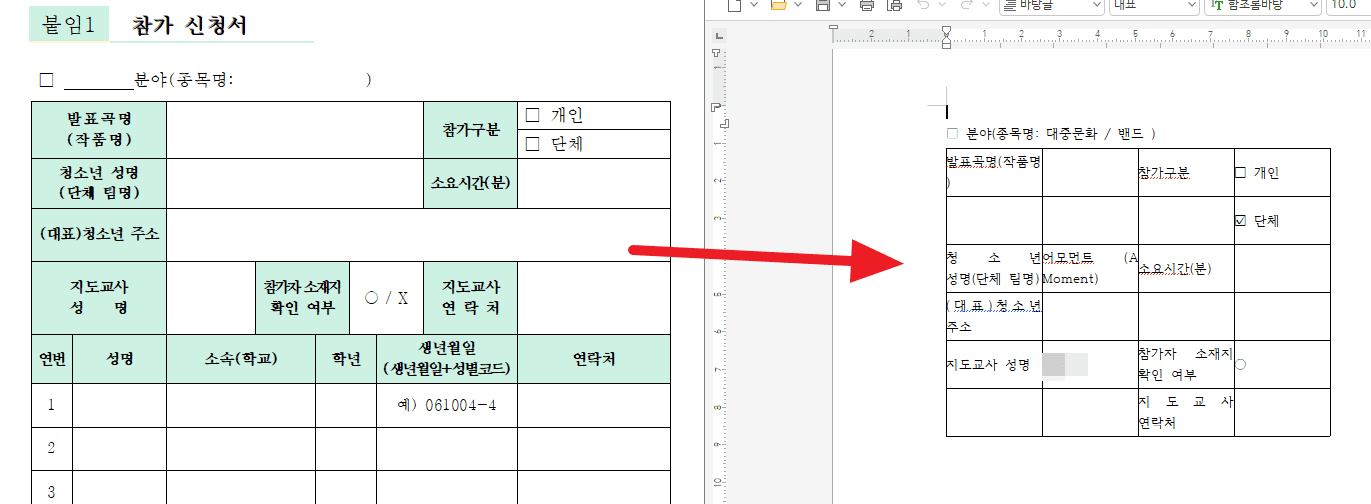
5. Conclusión
Probé a manejar documentos oficiales utilizando varias herramientas de IA y librerías.
Con la aparición de documentos estructurados como HWPX, la posibilidad de automatización es sin duda mayor que antes.
Pero las limitaciones siguen siendo claras.
Los documentos basados en HWP son estructuralmente desfavorables para la automatización y no son un formato adecuado para que la IA los comprenda de forma estable.
Hace poco vi en algún texto la frase: “No hay que criticar a Japón por haber desarrollado sellos que se pueden estampar en la pantalla”.
Yo también estoy de acuerdo con esto.
¿Vamos a seguir manteniendo un ecosistema tipo Galápagos para proteger el software nacional?
¿O vamos a aceptar un sistema de documentos basado en estándares internacionales?
Ha llegado el momento de que la administración pública se tome en serio esta cuestión.






댓글을 불러오는 중...