오랜만에 9월 모의고사를 풀다가 별의 광도 계급에 대한 문제가 나온 것을 보았다.
그래서 광도 계급에 대한 글을 써야겠다고 생각하다가, 고등학교 교육 과정에서 한발 더 나아가 광도 계급이 다르면 선폭이 다르게 나타나는 이유에 대해 글을 쓰기로 했다.
EBS 참고서에 보면 아래와 내용이 나온다.
오늘 쓰는 글은 아래 내용을 깊이 파보는 것이다. 글이 길기 때문에 2개의 주제로 쪼개어 봤다.
첫번째는 흡수선의 선폭을 결정하는 방법, 두번째는 광도 계급을 결정하는 방법이다.
광도 계급이 무엇인지 만을 알고 싶은 사람은 바로 결론의 링크로 가자.
같은 분광형을 가지는 별들의 스펙트럼에서 나타나는 흡수선의 선폭을 비교하여 별의 크기를 알 수 있고, 이를 비교하여 광도를 결정할 수 있다.
- EBS 수능특강 지구과학1 P.145 -
글을 읽기 전에 아래 글을 한번 읽고 오면 해당 글을 이해하는데 많은 도움을 줄 것이라고 생각한다.
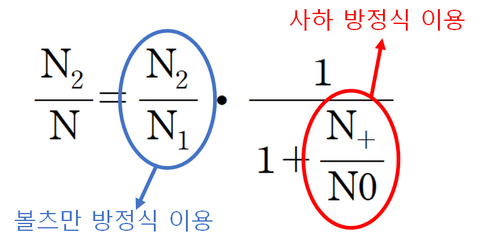
1. 스펙트럼 선과 흡수선의 선폭
먼저 우리가 일반적으로 보는 스펙트럼 선이 어떻게 만들어지는지를 알아야 한다. 분광 관측을 통해 별의 파장별 세기(플럭스)를 나타내면 아래와 같은 그래프를 보이게 된다.
별빛의 세기를 파장별로 나타내면 대략적으로 플랑크 곡선의 형태로 나타나는데, 별의 대기에 의해 흡수된 파장에서는 낮은 세기를 보이게 된다.

이때, 흡수가 일어나지 않았다면 보였을 일반적인 세기를 기준(Fc)으로 하고 각 (파장별 세기/일반적인 세기)(Fλ/Fc)를 이용하여 스펙트럼의 윤곽을 구한다.
이러한 식을 모든 파장에 대해 적용하면 별의 세기가 하나의 선형으로 나타나게 된다.
좀 더 쉽게 말하자면 별빛이 흡수된 정도를 1을 기준으로 나타낸 것이다.
이때 중심 파장(λ0)을 기준으로 나타나는 폭을 흡수선의 선폭(∆λ)이라고 정의한다.
그리고 중심 파장을 기준으로 흡수선의 세기와 동일한 면적을 가지는 그래프를 그렸을 때 그래프의 폭을 등가폭(Wλ)이라고 정의한다.

각 원자별 흡수선의 등가폭을 스펙트럼에 나타내면 일반적으로 알고 있는 흡수 스펙트럼이 나타나는 것이다.
교육과정에서 배운 흡수 스펙트럼의 세기는 등가폭을 말한다.
그런데 광도 계급에서 이야기하는 것은 흡수선의 선폭이다.
그렇다면 흡수선의 선폭은 어떤 요소로 결정되는 것일까?

2. 흡수선의 선폭 증가의 요인
위의 글에서 보듯이 흡수선은 하나의 가느다란 선으로 나타나지 않고 그보다 넓은파장 범위에서 나타난다.
예를들어 수소원자가 에너지 준위 n=2 ➜ n=3으로 들뜨면서 흡수한 흡수선이 있다고 가정해보자.
흡수선의 중심 파장은 λ=656.3nm일 것이다.
하지만 이 흡수선이 λ=656.3nm에만 나타나는 것이 아니라 범위를 가지고 나타난다는 것이다.

스펙트럼에서 흡수선이 완전한 선으로 나타나지 않는 이유를 몇가지 적어 보겠다.
아래와 같은 이유 때문에 스펙트럼의 흡수선은 하나의 파장을 중심으로 옆으로 넓게 퍼진 듯한 형태를 보이는데, 이때 중심 파장으로 부터의 넓이를 흡수선의 선폭이라고 부른다.
1) 자연 선폭 증가
불확정성의 원리에 의해 원자의 에너지 준위를 정확하게 결정할 수 없다.
따라서 많은 원자에 의한 흡수선도 하나의 파장을 중심으로 선폭이 발생한다.


2) 열적 도플러 선폭 증가
기체 원자는 끊임없이 운동한다.
이때 원자의 운동 속도는 온도와 화학적 조성과 관련이 있다.
입자의 시선 방향에 의한 도플러 효과가 선폭 증가를 가져온다.

3) 충돌 선폭 증가(슈타르크 효과)
원자의 에너지 준위가 인접한 주위 원자에 의해 변화된다.
주위의 원자가 많을 수록, 그리고 더 가까울 수록 다양한 에너지 준위를 만들어내고 이에 의해 선폭이 증가하는 효과가 발생한다.
따라서 충돌 선폭 증가는 밀도가 높을수록(압력이 높을수록) 더 많은 선폭 증가를 가져온다.
4) 제만 효과
원자가 강한 자기장에 놓여 있을 때 에너지 준위가 3개 이상으로 갈라지는 현상이다.
자기장이 강한 별에서는 제만 효과로 인해 선폭이 증가하는 현상이 발생한다.
3. 요악 및 마무리
별의 흡수선은 하나의 가느다란 선으로 나타는 것이 아니라 폭을 가지고 나타나는데 이것을 선폭이라고 한다.
흡수선의 선폭은 네 가지 요인(자연 선폭 증가, 열적 도플러 효과, 슈타르크 효과, 제만 효과)에 영향을 받는다.
별의 광도 계급은 네 가지 요인 중 슈타르크 효과와 관계가 있다. 흡수선을 만드는 기체의 압력이 높으면 높을수록 선폭이 넓어지는 것을 슈타르크 효과라고 한다.
이번 글에서는 흡수선의 선폭이 어떻게 결정되고, 어떤 요인에 영향을 받는지 알아봤다.
흡수선의 선폭을 통해 어떻게 광도계급을 결정하게 되었는지를 알고 싶다면 다음 글을 읽어보자.






댓글을 불러오는 중...