이전에는 파이썬을 할 줄 아는데 굳이 R을 배워야 하는가에 대한 의문이 있었다.
이번 연수를 들으며, 연구할 때 굳이 파이썬을 쓸 필요가 없다는 것을 깨닫게 되었다.
파이썬 같으면 numpy로 선형회귀하고, 그래프 그리고, P value 구하고 다 해야 하지만 R은 lm과 summary 한방이면 끝난다.
그래서 오늘은 이때까지 배운 R 실습과 관련된 내용들을 총복습하고, 실제 데이터를 활용해 연습 예제를 보여주려고 한다.
1. 예제 데이터
예제 데이터는 카글에 올라와 있는 미국 학생의 성적 데이터이다.
혹시 카글에 가입되어 있지 않은 사람을 위해 아래에 링크를 걸어둔다.
이 데이터는 부모의 배경, 시험 준비 코스 등 학생의 성적에 주는 영향을 보기 위해 만들어졌다고 한다.
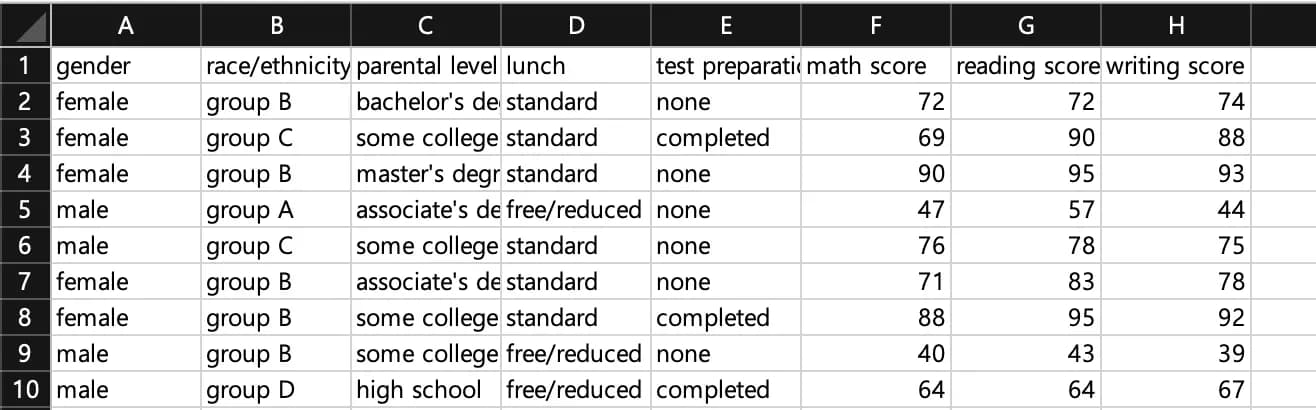
아래에 데이터 내부 값들을 붙여놨다.
간단하게 설명하자면 gender는 학생의 성별, race는 인종, parental level은 부모의 학력, lunch는 급식의 가격, test preparation은 시험 준비코스 수료 여부이다.
2. R studio에서 csv파일 열기
R studio에서 파일을 불러오는 명령어는 read이다.
파일 경로를 넣는게 귀찮으면, 그냥 파일을 클릭한 상태로 복사 한 뒤 붙여넣기를 누르면 경로가 들어간다.
혹은 file.choose() 명령어를 이용해 윈도우에서 골라줄 수도 있다.
참고로 각 줄에서의 명령어 실행은 ctrl + enter(Mac에서 cmd + enter)를 해주면 된다.
data <- read.csv("파일경로")
// dat <- read.csv(file.choose())
head(data)
3. 선형회귀분석
이제 이 데이터로 간단한 선형회귀를 해보자.
lm이라는 함수는 내부 파라미터로 lm(종속변수 ~ 독립변수, 데이터시트) 를 순차적으로 받는다.
예를들어 수학점수와 영어점수간의 상관관계를 한번 살펴본다고 한다면 아래와 같이 실행하면 된다.
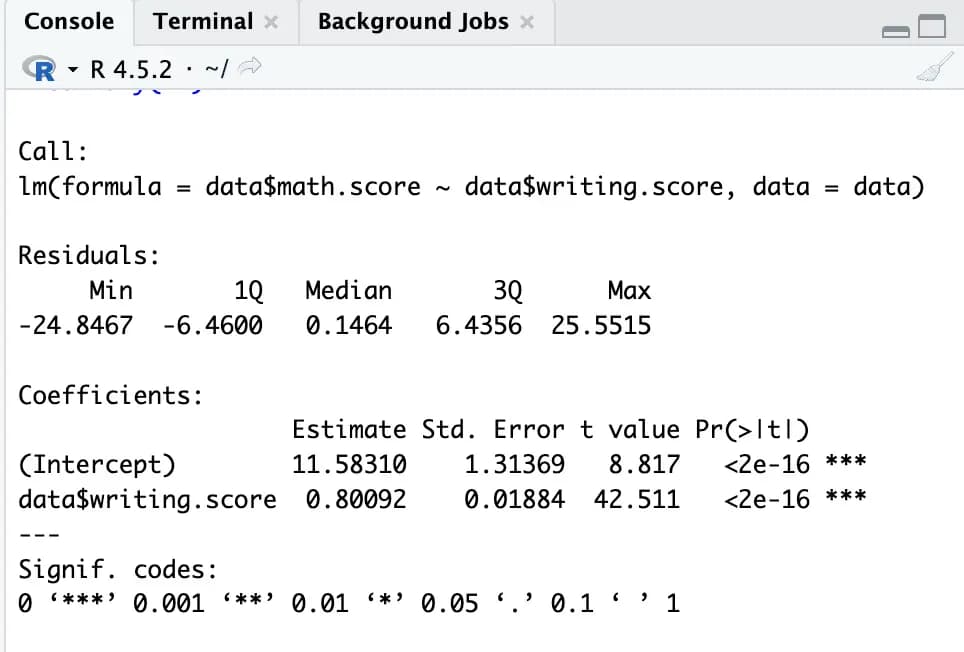
m1 <- lm(data$math.score ~ data$writing.score, data)
summary(m1)이렇게 하면 정말 간단하게 선형회귀 분석이 끝났다.
오류, t-test, p-value 까지 아무것도 설정하지 않아도 논문에 넣을 수 있을 정도로 값들이 나와서 무척 편하다.
4. 차트 그리기
그래프도 정말 간단하게 그려볼 수 있다.
단순히 plot(m1) 을 입력하기만 해도 필요한 차트들을 대부분 그려준다.
원하는 데이터가 따로 있다면, x축 값과 y축 값을 순차적으로 콤마로 구분해 넣으면 된다.
5. 중다회귀분석
변인이 많을 때는 lm 의 독립변수 파라미터 위치에서 모든 값을 +로 구분해 넣어준다.
예를들어 쓰기 점수에 대해 읽기 점수와 수학 점수의 영향을 보고자 한다면 아래와 같이 분석 가능하다.
m2 <- lm(data$writing.score ~ data$reading.score + data$math.score, data)
summary(m2)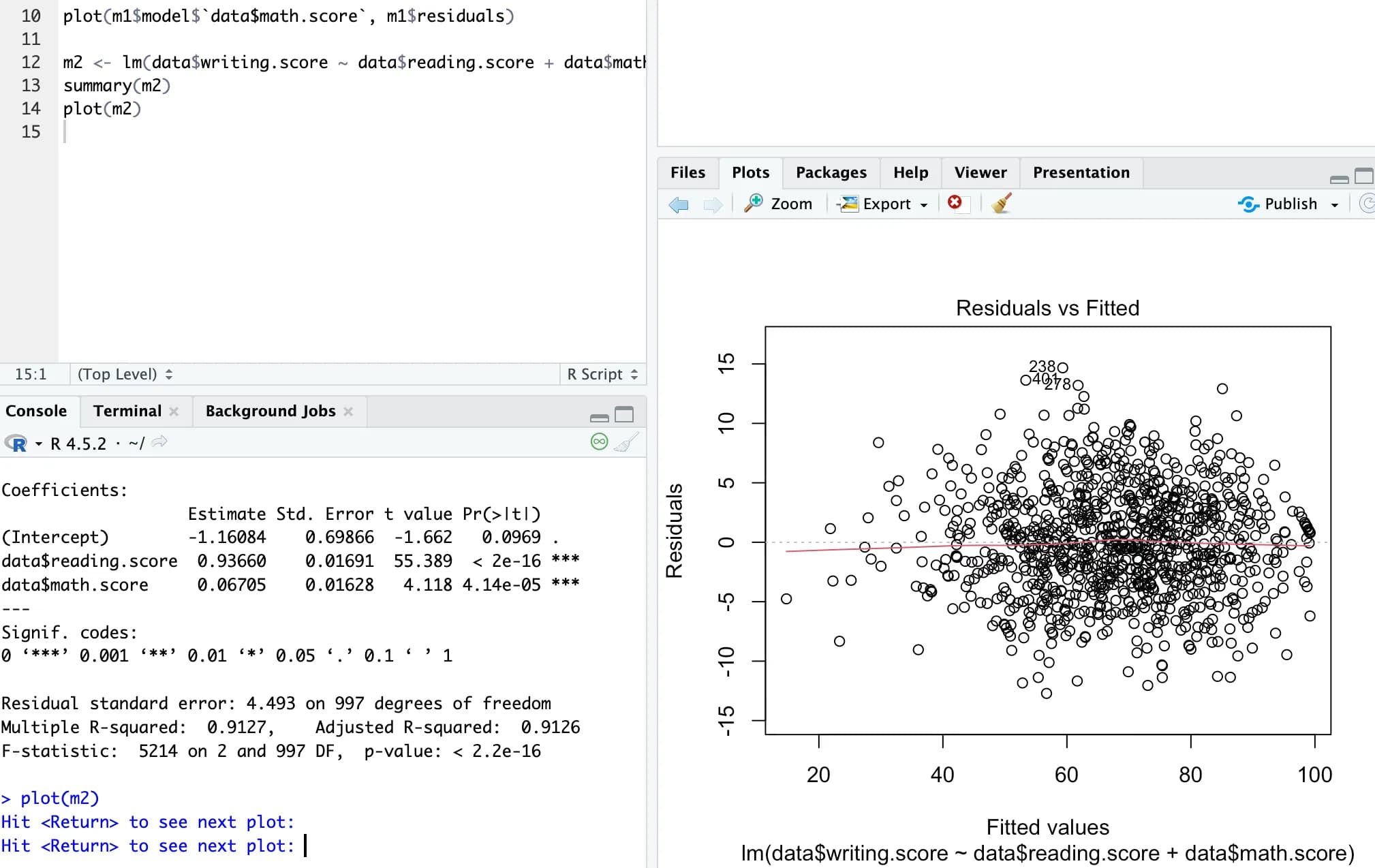
6. 범주변수 처리(수가 아닌 데이터 처리)
범주변수란, 데이터를 질적인 그룹이나 그룹으로 나누는 변수이다.
이는 성별, 학력과 같은 숫자가 아닌 데이터들을 처리하기 위함이다.
여기서는 가장 쉬운 성별을 처리해보자.
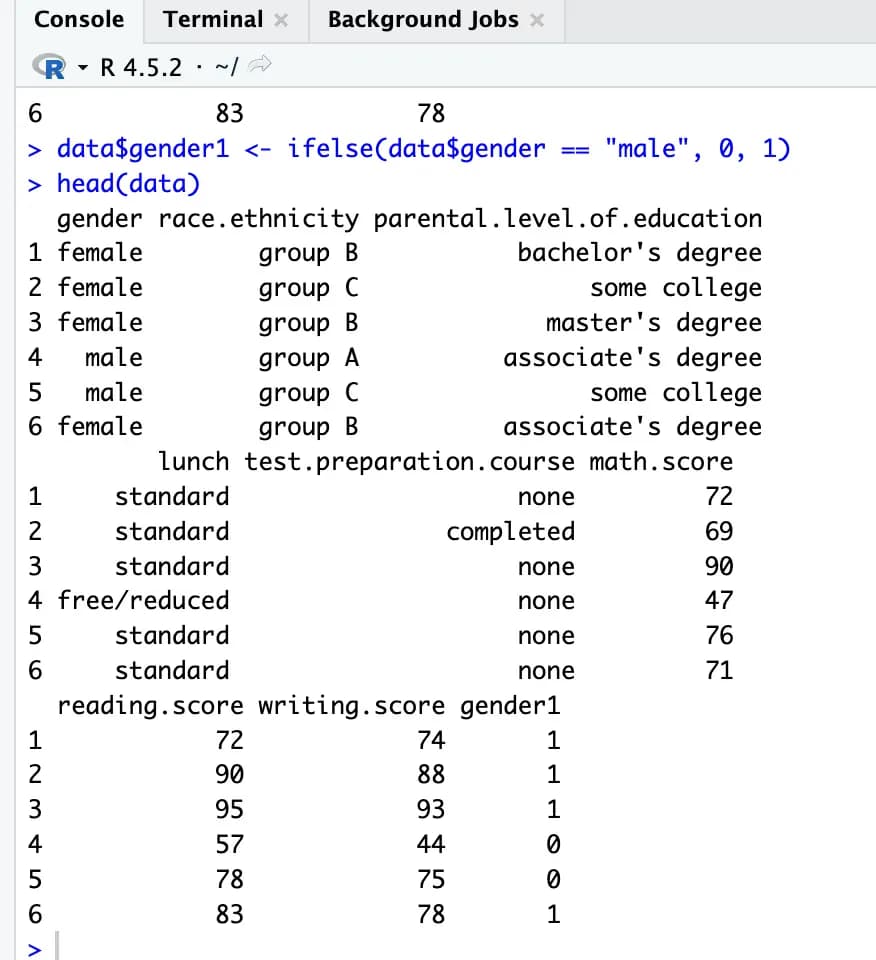
ifelse()함수를 이용해 더미 데이터인 gender1을 data에 주입해준다.
data$gender1 <- ifelse(data$gender == "male", 0, 1)
// 첫번째 조건이 참일경우 0, 거짓일 경우 1을 입력
head(data)이렇게 한 뒤 테이블을 확인해보면 gender1 테이블이 새롭게 생기고, 여성일 경우 1, 남성일 경우 0이 채워져 있는 것을 알 수 있다.
이제 이것을 이용해 선형회귀분석을 해볼수 있다.
그런데 재밌는건, 굳이 이렇게 하지 않고 gender를 그대로 집어넣어도 분석이 된다.
m3 <- lm(data$math.score ~ data$gender, data)
plot(m3)이는 R이 위에서 우리가 처리한 것처럼 문자형 데이터를 처리한 뒤 분석하기 때문이다.

성별은 단 2개이기 때문에 쉽지만, 부모의 학력이나 그룹과 같이 여러 항목이 있을 경우는 조금 다르다.
만약 n개의 항목이 있다면, n-1개의 더미변수가 더 필요하다.
만들 수는 있지만, 그냥 R에게 나의 영혼을 맡기는 것도 나쁘지 않은 듯 하다.
m4 <- lm(data$math.score ~ data$race.ethnicity, data)
summary(m4)
plot(m4)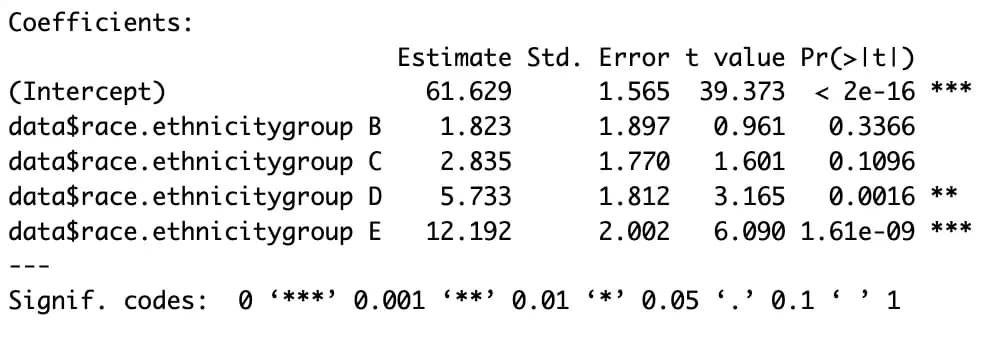
7. resid를 이용한 잔차 계산과 활용
resid를 이용하면 선형회귀곡선에 대한 각 항의 잔차를 계산할 수 있다.
잔차를 활용해 자료가 선형적인지, 분산이 어떤지를 확인할 수 있다.
먼저 데이터를 분석한 뒤, 변인 하나와 분석 결과를 활용해 잔차를 계산하고 그래프를 그려보자.
m5 <- lm(data$math.score ~ data$writing.score, data)
res1 <- resid(m5)
plot(data$writing.score, res1)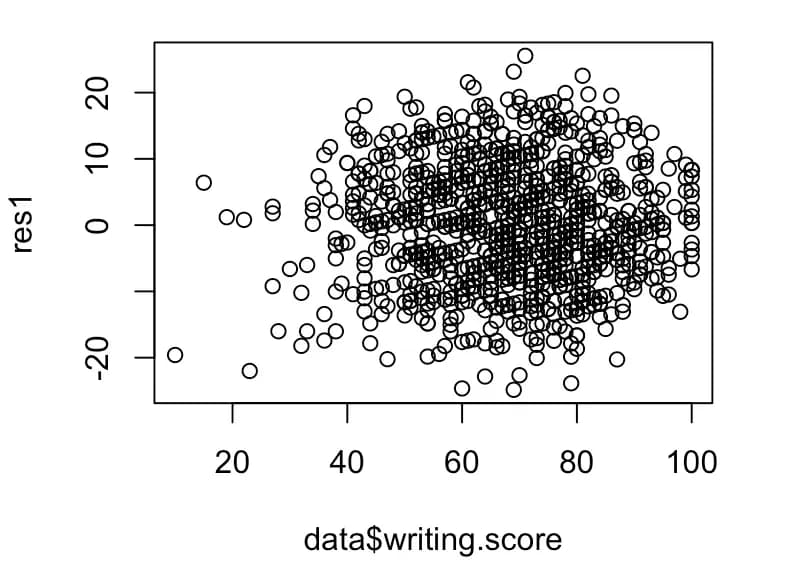
이렇게 그래프를 그려보니, 실제 데이터의 분산이 등분산적이지 않다.
이 때는 각 값에 대해 축의 크기를 조절해 주어야 한다.
8. R을 이용한 상호작용 분석 - 단계적 회귀분석
단계적 회귀 분석은 변수를 하나씩 추가해가면서 영향력을 확인하는 것이다.
연구자가 하나씩 추가하면서 할 수도 있지만, R에서는 자동으로 다 해준다.
m7 <- lm(data$math.score ~ ., data)
m8 <- step(m7, direction = "both")
summary(m8)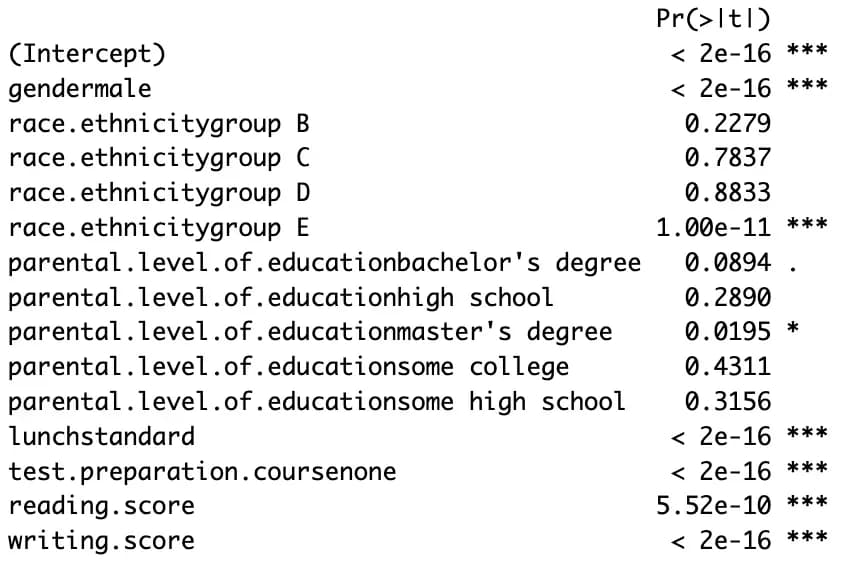
이 방법은 쉽지만 해석이 난해하다.
그래서 연구자의 의도에 따라 분석하는 위계적 회귀분석을 더 선호한다고 한다.
9. 후기
그냥 단계적 회귀분석 때려넣어서 제일 잘 설명하는 모델 고른 다음 p-value가 가장 낮은 방향으로 결론 지으면 될 것 같았는데 아니었다.
R이 편하긴 하지만, 결론을 얻기 위해서는 연구자의 사고 과정이 무척 중요하다는 생각이 들었다.
공부를 하기 전에는 R을 배우지 않고 파이썬으로 모든걸 해결할 수 있을거라 생각했는데 크나큰 오산이었다.
나는 R을 찬양하게 되었다.






댓글을 불러오는 중...